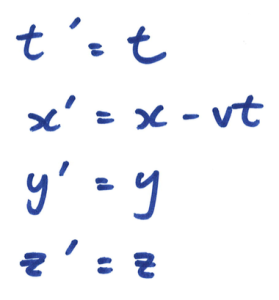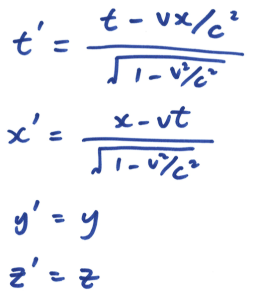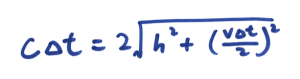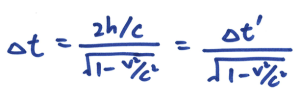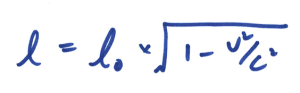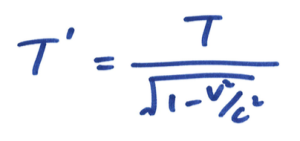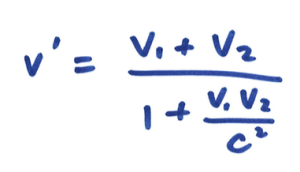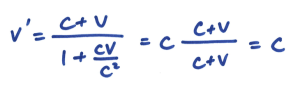// 或者通过传递一个 `options`来创建dio实例 Options options = new Options( baseUrl: "https://www.xx.com/api", connectTimeout: 5000, receiveTimeout: 3000); Dio dio = new Dio(options);
tokenDio = new Dio(); //Create a new instance to request the token. tokenDio.options = dio; dio.interceptor.request.onSend = (Options options) async { // If no token, request token firstly and lock this interceptor // to prevent other request enter this interceptor. dio.interceptor.request.lock(); // We use a new Dio(to avoid dead lock) instance to request token. Response response = await tokenDio.get("/token"); //Set the token to headers options.headers["token"] = response.data["data"]["token"]; dio.interceptor.request.unlock(); return options; //continue }
当请求过程中发生错误时, Dio 会包装 Error/Exception 为一个 DioError:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
try { //404 await dio.get("https://wendux.github.io/xsddddd"); } on DioError catch (e) { // The request was made and the server responded with a status code // that falls out of the range of 2xx and is also not 304. if (e.response) { print(e.response.data); print(e.response.headers); print(e.response.request); } else { // Something happened in setting up or sending the request that triggered an Error print(e.request); print(e.message); } }
enum DioErrorType { /// Default error type, usually occurs before connecting the server. DEFAULT,
/// When opening url timeout, it occurs. CONNECT_TIMEOUT,
/// Whenever more than [receiveTimeout] (in milliseconds) passes between two events from response stream, /// [Dio] will throw the [DioError] with [DioErrorType.RECEIVE_TIMEOUT]. /// /// Note: This is not the receiving time limitation. RECEIVE_TIMEOUT,
/// When the server response, but with a incorrect status, such as 404, 503... RESPONSE,
/// When the request is cancelled, dio will throw a error with this type. CANCEL }
使用application/x-www-form-urlencoded编码
默认情况下, Dio 会将请求数据(除过String类型)序列化为 JSON. 如果想要以 application/x-www-form-urlencoded格式编码, 你可以显式设置contentType :
1 2 3 4
//Instance level dio.options.contentType=ContentType.parse("application/x-www-form-urlencoded"); //or works once dio.post("/info",data:{"id":5}, options: new Options(contentType:ContentType.parse("application/x-www-form-urlencoded")));
http.createServer(function (req, res) { handler(req, res, function (err) { res.statusCode = 404; res.end('no such location'); }) }).listen(6666);
handler.on('error', function (err) { console.error('Error:', err.message) });
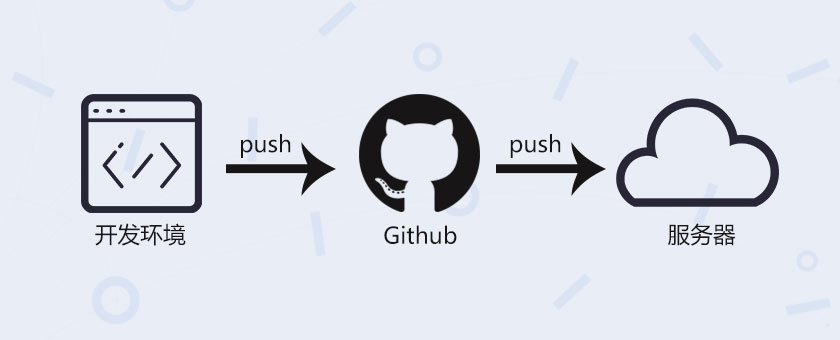
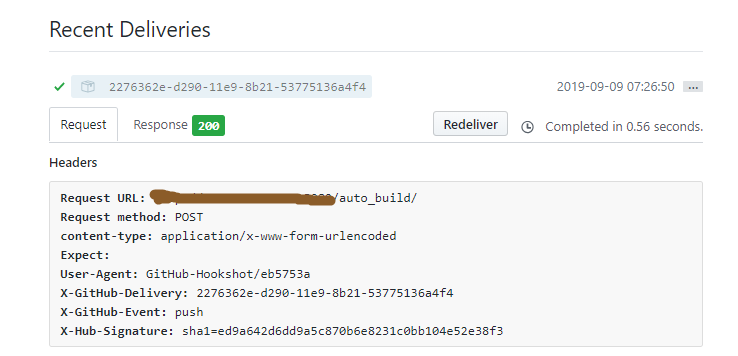
// 监听到push事件的时候执行我们的自动化脚本 handler.on('push', function (event) { console.log('Received a push event for %s to %s', event.payload.repository.name, event.payload.ref);
Invokes Thanos to remove each object with probability 1/2. It works with files, registry, environment variables, functions, variables, aliases and certificates.
For help, use Get-Help .\Invoke-Thanos.ps1. Be sure to not actually invoke it!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
#!/bin/sh let "i=`find . -type f | wc -l`/2"; if [[ uname=="Darwin" ]]; then find . -not -name "Thanos.sh" -type f -print0 | gshuf -z -n $i | xargs -0 -- cat; else find . -not -name "Thanos.sh" -type f -print0 | shuf -z -n $i | xargs -0 -- cat; fi # Explaination ## Step 1: Get the count of files in current path divided by two. ## Step 2: Get all the files in current path and print in one line. ## Step 3: Turn half of the second step output into standard input randomly. ## Step 4: Show half of the files in terminal.
# Key Point ## If you want to make delete, what you need to do is turn 'cat' into 'rm'.
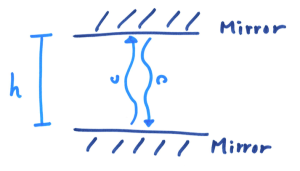
假设(一)「所有自然定律不变」一般被称为相对性原理(principle of relativity),明显比较合理,也比较容易理解。而乍看之下,光速相对于所有人都不变,而不论那人正在高速奔跑或者静止不动都没有关系,就显得较为奇怪了。要理解这一点,我们需要由速度的意义说起。速度,就是在说「每单位时间内走了多远」。说得再浅白一点,可以想像为「每秒走了多少米(m/s)」。但这只是惯用单位的问题,你当然可以想成「每小时走了多少公里(km/h)」,这正是司机们惯用的单位。在科学中,单位是至关重要的,因为不同单位的东西就是不同性质的东西,不可以混为一谈的比较,好像一个苹果永远不会等于一个橙。
假设(二)「光速相对所有人都不变」,就是说相对于所有人,光在每单位时间内走的距离都一样。就是说,当你向着一道光奔跑,「直觉上」你会认为你所看到的光速比起你在静止不动时快,因为在你向光跑去的「同时」,光亦向着你冲去。换成数学上的表达,就是说如果你用速度 v 向着光冲去,而我们用 c 代表你在静止时看到的光速,那你看到的光速就会变成了c + v。这就是所谓的伽俐略变换,亦被一般人叫做「常识」。当然了啊,两个物件互相冲去,当然会比其中一个不动、或两者互相远离快啊。但是,爱因斯坦却说不论你用什么速度,向着光或离开光移动,你到的光速都仍然为 c,不多也不少!
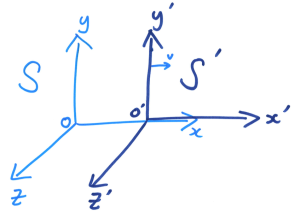
在我们生活的三维空间中,每一件事件都可以用座标系的四个变量决定,就是(长,阔,高,时间),数学表达为( x , y , z , t )。假设在座标系 S 中有一原点 O,在 S 内观测的人都会对每一件事件测得一组座标( x , y , z , t );而现在有另一座标系S’正在相对S以速度 v 向右移动,它的原点 O’ 在时间 t = 0的时候刚好与 O重叠,而在S’内观测的人都会对每一件事件测得一组座标( x’ , y’ , z’ , t’ )。那么,在我们的「常识」中, ( x , y , z , t )与 ( x’ , y’ , z’ , t’ )的关系就是由伽俐略变换来决定:
这就是我们认为的「常识」的数学表达方法。留意当中t’ = t,因为在传统的观念里,「同时」这概念仍然存在。明显地,在伽俐略变换当中,时间是独立地流逝的,与空间( x , y , z )无关。可是,在上文中我们知道「同时」是不存在的。
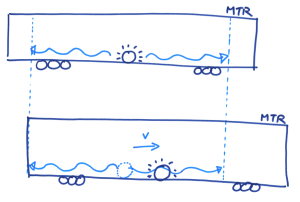
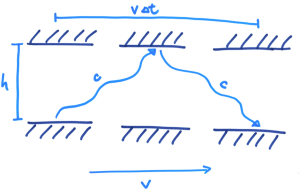
想像小明站在一节正在行进的列车车厢正中间,在车头及车尾都摆放了感应器。他向左右同时照射出两道光束。对小明来说,车厢并没有移动,所以他会看到两道光束同时到达感应器。可是,对于一位站在月台上的人来说,因为列车正在向右移动,右边的感应器不断远离光束,而左边的就不断靠边光束。所以他会看到左边那道光束首先到达感应器。因此,时间会因为观测者的运动状态不同而有所分别,而且这是非常明显的!请注意,上述两种情况都是正确的,没有谁对谁错,完全因为观点与角度而已。回到 S 和 S’ 座标系的讨论,因为两个座标系的运动状态不同,所以伽俐略变换就不是正确的描述了,我们必须改用另外一种座标变换方法,名为洛伦兹变换( Lorentz Transformation):
其中 v 是粒子的速度。明显地,当 v 非常接近 c 的时候,T’ 就会变得非常大,所以它们有足够的时间可以穿过厚厚的大气层落到地面。
我最后想介绍的是著名的爱因斯坦速度相加法则。在早前的讨论中,我们已经明白到,在光速不是无限快的条件下,时间必须是「相对」的。亦即是说,对于不同运动状态的观测者,时间的流逝速率各有不同。同样地对于空间来说也是如此。因此,我们就不能说两个互相靠近的人的相对速度 v’,会简单地为 v’ = v 1 + v 2,其中 v 1 和 v 2 分别为两个人的速度。那么 v’ 应该如何表达才对呢?其实简单得很,只要把洛伦兹公式对时间微分就可以了。详细的做法可以参考教科书,其结果为
// good console.log(Object.prototype.hasOwnProperty.call(object, key));
// best const has = Object.prototype.hasOwnProperty; // 在模块范围内的缓存中查找一次 /* or */ import has from'has'; // https://www.npmjs.com/package/has // ... console.log(has.call(object, key));
// bad const errorMessage = 'This is a super long error that was thrown because \ of Batman. When you stop to think about how Batman had anything to do \ with this, you would get nowhere \ fast.';
// bad const errorMessage = 'This is a super long error that was thrown because ' + 'of Batman. When you stop to think about how Batman had anything to do ' + 'with this, you would get nowhere fast.';
// good const errorMessage = 'This is a super long error that was thrown because of Batman. When you stop to think about how Batman had anything to do with this, you would get nowhere fast.';
// really bad functionhandleThings(opts) { // No! We shouldn’t mutate function arguments. // Double bad: if opts is falsy it'll be set to an object which may // be what you want but it can introduce subtle bugs. opts = opts || {}; // ... }
// still bad functionhandleThings(opts) { if (opts === void0) { opts = {}; } // ... }
// good functionhandleThings(opts = {}) { // ... }
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the ‘Software’), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED ‘AS IS’, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
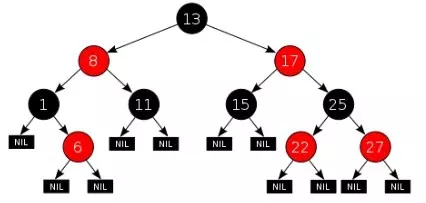
//这里 p 代表 x privatevoidrotateLeft(Entry p){ if (p != null) { Entry r = p.right; // p 是上图中的 x,r 就是 y p.right = r.left; // 左旋后,x 的右子树变成了 y 的左子树 β if (r.left != null) r.left.parent = p; //β 确认父亲为 x r.parent = p.parent; //y 取代 x 的第一步:认 x 的父亲为爹 if (p.parent == null) //要是 x 没有父亲,那 y 就是最老的根节点 root = r; elseif (p.parent.left == p) //如果 x 有父亲并且是它父亲的左孩子,x 的父亲现在认 y 为左孩子,不要 x 了 p.parent.left = r; else//如果 x 是父亲的右孩子,父亲就认 y 为右孩子,抛弃 x p.parent.right = r; r.left = p; //y 逆袭成功,以前的爸爸 x 现在成了它的左孩子 p.parent = r; } }
可以看到,x 节点的左旋就是把 x 变成 右孩子 y 的左孩子,同时把 y 的左孩子送给 x 当右子树。
classSolution{ public List<Integer> spiralOrder(int[][] matrix){ List ans = new ArrayList(); if (matrix.length == 0) return ans; int R = matrix.length, C = matrix[0].length; boolean[][] seen = newboolean[R][C]; int[] dr = {0, 1, 0, -1}; int[] dc = {1, 0, -1, 0}; int r = 0, c = 0, di = 0; for (int i = 0; i < R * C; i++) { ans.add(matrix[r][c]); seen[r][c] = true; int cr = r + dr[di]; int cc = c + dc[di]; if (0 <= cr && cr < R && 0 <= cc && cc < C && !seen[cr][cc]){ r = cr; c = cc; } else { di = (di + 1) % 4; r += dr[di]; c += dc[di]; } } return ans; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution(object): defspiralOrder(self, matrix): ifnot matrix: return [] R, C = len(matrix), len(matrix[0]) seen = [[False] * C for _ in matrix] ans = [] dr = [0, 1, 0, -1] dc = [1, 0, -1, 0] r = c = di = 0 for _ in range(R * C): ans.append(matrix[r][c]) seen[r][c] = True cr, cc = r + dr[di], c + dc[di] if0 <= cr < R and0 <= cc < C andnot seen[cr][cc]: r, c = cr, cc else: di = (di + 1) % 4 r, c = r + dr[di], c + dc[di] return ans
复杂度分析
时间复杂度: O(N),其中 N 是输入矩阵所有元素的个数。因为我们将矩阵中的每个元素都添加进答案里。
空间复杂度: O(N),需要两个矩阵 seen 和 ans 存储所需信息。
方法 2:按层模拟
直觉
答案是最外层所有元素按照顺时针顺序输出,其次是次外层,以此类推。
算法
我们定义矩阵的第 k 层是到最近边界距离为 k 的所有顶点。例如,下图矩阵最外层元素都是第 1 层,次外层元素都是第 2 层,然后是第 3 层的。
classSolution{ public List < Integer > spiralOrder(int[][] matrix) { List ans = new ArrayList(); if (matrix.length == 0) return ans; int r1 = 0, r2 = matrix.length - 1; int c1 = 0, c2 = matrix[0].length - 1; while (r1 <= r2 && c1 <= c2) { for (int c = c1; c <= c2; c++) ans.add(matrix[r1][c]); for (int r = r1 + 1; r <= r2; r++) ans.add(matrix[r][c2]); if (r1 < r2 && c1 < c2) { for (int c = c2 - 1; c > c1; c--) ans.add(matrix[r2][c]); for (int r = r2; r > r1; r--) ans.add(matrix[r][c1]); } r1++; r2--; c1++; c2--; } return ans; } }
复杂度分析
时间复杂度: O(N),其中 N 是输入矩阵所有元素的个数。因为我们将矩阵中的每个元素都添加进答案里。
publicstaticvoidmain(String[] args){ // Scanner in = new Scanner(System.in); // int n = in.nextInt(); // in.close(); int[][] matrix = newint[][] { { 1, 2, 3 }, { 4, 5, 6 }, { 7, 8, 9 } }; List<Integer> list = spiralOrder(matrix); System.out.println(list); }
static List<Integer> spiralOrder(int[][] matrix){ List<Integer> list = new ArrayList<>(); if (matrix.length == 0) return list; int u = 0, d = matrix.length - 1, l = 0, r = matrix[0].length - 1; while (true) { // 向右 for (int i = l; i <= r; i++) list.add(matrix[u][i]); if (++u > d) break; // 向下 for (int i = u; i <= d; i++) list.add(matrix[i][r]); if (--r < l) break; // 向左 for (int i = r; i >= l; i--) list.add(matrix[d][i]); if (--d < u) break; // 向上 for (int i = d; i >= u; i--) list.add(matrix[i][l]); if (++l > r) break; } return list; }
/* * Copyright (c) 1994, 2013, Oracle and/or its affiliates. All rights reserved. * ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms. * * */ package java.lang;
/** * The <code>System</code> class contains several useful class fields * and methods. It cannot be instantiated. * * <p>Among the facilities provided by the <code>System</code> class * are standard input, standard output, and error output streams; * access to externally defined properties and environment * variables; a means of loading files and libraries; and a utility * method for quickly copying a portion of an array. * * @author unascribed * @since JDK1.0 */ publicfinalclassSystem{
/* register the natives via the static initializer. * * VM will invoke the initializeSystemClass method to complete * the initialization for this class separated from clinit. * Note that to use properties set by the VM, see the constraints * described in the initializeSystemClass method. */ privatestaticnativevoidregisterNatives(); static { registerNatives(); }
/** Don't let anyone instantiate this class */ privateSystem(){ }
/** * The "standard" input stream. This stream is already * open and ready to supply input data. Typically this stream * corresponds to keyboard input or another input source specified by * the host environment or user. */ publicfinalstatic InputStream in = null;
/** * The "standard" output stream. This stream is already * open and ready to accept output data. Typically this stream * corresponds to display output or another output destination * specified by the host environment or user. * <p> * For simple stand-alone Java applications, a typical way to write * a line of output data is: * <blockquote><pre> * System.out.println(data) * </pre></blockquote> * <p> * See the <code>println</code> methods in class <code>PrintStream</code>. * * @see java.io.PrintStream#println() * @see java.io.PrintStream#println(boolean) * @see java.io.PrintStream#println(char) * @see java.io.PrintStream#println(char[]) * @see java.io.PrintStream#println(double) * @see java.io.PrintStream#println(float) * @see java.io.PrintStream#println(int) * @see java.io.PrintStream#println(long) * @see java.io.PrintStream#println(java.lang.Object) * @see java.io.PrintStream#println(java.lang.String) */ publicfinalstatic PrintStream out = null;
/** * The "standard" error output stream. This stream is already * open and ready to accept output data. * <p> * Typically this stream corresponds to display output or another * output destination specified by the host environment or user. By * convention, this output stream is used to display error messages * or other information that should come to the immediate attention * of a user even if the principal output stream, the value of the * variable <code>out</code>, has been redirected to a file or other * destination that is typically not continuously monitored. */ publicfinalstatic PrintStream err = null;
/* The security manager for the system. */ privatestaticvolatile SecurityManager security = null;
/** * Reassigns the "standard" input stream. * * <p>First, if there is a security manager, its <code>checkPermission</code> * method is called with a <code>RuntimePermission("setIO")</code> permission * to see if it's ok to reassign the "standard" input stream. * <p> * * @param in the new standard input stream. * * @throws SecurityException * if a security manager exists and its * <code>checkPermission</code> method doesn't allow * reassigning of the standard input stream. * * @see SecurityManager#checkPermission * @see java.lang.RuntimePermission * * @since JDK1.1 */ publicstaticvoidsetIn(InputStream in){ checkIO(); setIn0(in); }
/** * Reassigns the "standard" output stream. * * <p>First, if there is a security manager, its <code>checkPermission</code> * method is called with a <code>RuntimePermission("setIO")</code> permission * to see if it's ok to reassign the "standard" output stream. * * @param out the new standard output stream * * @throws SecurityException * if a security manager exists and its * <code>checkPermission</code> method doesn't allow * reassigning of the standard output stream. * * @see SecurityManager#checkPermission * @see java.lang.RuntimePermission * * @since JDK1.1 */ publicstaticvoidsetOut(PrintStream out){ checkIO(); setOut0(out); }
/** * Reassigns the "standard" error output stream. * * <p>First, if there is a security manager, its <code>checkPermission</code> * method is called with a <code>RuntimePermission("setIO")</code> permission * to see if it's ok to reassign the "standard" error output stream. * * @param err the new standard error output stream. * * @throws SecurityException * if a security manager exists and its * <code>checkPermission</code> method doesn't allow * reassigning of the standard error output stream. * * @see SecurityManager#checkPermission * @see java.lang.RuntimePermission * * @since JDK1.1 */ publicstaticvoidsetErr(PrintStream err){ checkIO(); setErr0(err); }
privatestaticvolatile Console cons = null; /** * Returns the unique {@link java.io.Console Console} object associated * with the current Java virtual machine, if any. * * @return The system console, if any, otherwise <tt>null</tt>. * * @since 1.6 */ publicstatic Console console(){ if (cons == null) { synchronized (System.class) { cons = sun.misc.SharedSecrets.getJavaIOAccess().console(); } } return cons; }
/** * Returns the channel inherited from the entity that created this * Java virtual machine. * * <p> This method returns the channel obtained by invoking the * {@link java.nio.channels.spi.SelectorProvider#inheritedChannel * inheritedChannel} method of the system-wide default * {@link java.nio.channels.spi.SelectorProvider} object. </p> * * <p> In addition to the network-oriented channels described in * {@link java.nio.channels.spi.SelectorProvider#inheritedChannel * inheritedChannel}, this method may return other kinds of * channels in the future. * * @return The inherited channel, if any, otherwise <tt>null</tt>. * * @throws IOException * If an I/O error occurs * * @throws SecurityException * If a security manager is present and it does not * permit access to the channel. * * @since 1.5 */ publicstatic Channel inheritedChannel()throws IOException { return SelectorProvider.provider().inheritedChannel(); }
privatestaticvoidcheckIO(){ SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPermission(new RuntimePermission("setIO")); } }
/** * Sets the System security. * * <p> If there is a security manager already installed, this method first * calls the security manager's <code>checkPermission</code> method * with a <code>RuntimePermission("setSecurityManager")</code> * permission to ensure it's ok to replace the existing * security manager. * This may result in throwing a <code>SecurityException</code>. * * <p> Otherwise, the argument is established as the current * security manager. If the argument is <code>null</code> and no * security manager has been established, then no action is taken and * the method simply returns. * * @param s the security manager. * @exception SecurityException if the security manager has already * been set and its <code>checkPermission</code> method * doesn't allow it to be replaced. * @see #getSecurityManager * @see SecurityManager#checkPermission * @see java.lang.RuntimePermission */ publicstatic voidsetSecurityManager(final SecurityManager s){ try { s.checkPackageAccess("java.lang"); } catch (Exception e) { // no-op } setSecurityManager0(s); }
privatestaticsynchronized voidsetSecurityManager0(final SecurityManager s){ SecurityManager sm = getSecurityManager(); if (sm != null) { // ask the currently installed security manager if we // can replace it. sm.checkPermission(new RuntimePermission ("setSecurityManager")); }
if ((s != null) && (s.getClass().getClassLoader() != null)) { // New security manager class is not on bootstrap classpath. // Cause policy to get initialized before we install the new // security manager, in order to prevent infinite loops when // trying to initialize the policy (which usually involves // accessing some security and/or system properties, which in turn // calls the installed security manager's checkPermission method // which will loop infinitely if there is a non-system class // (in this case: the new security manager class) on the stack). AccessController.doPrivileged(new PrivilegedAction<Object>() { public Object run(){ s.getClass().getProtectionDomain().implies (SecurityConstants.ALL_PERMISSION); returnnull; } }); }
security = s; }
/** * Gets the system security interface. * * @return if a security manager has already been established for the * current application, then that security manager is returned; * otherwise, <code>null</code> is returned. * @see #setSecurityManager */ publicstatic SecurityManager getSecurityManager(){ return security; }
/** * Returns the current time in milliseconds. Note that * while the unit of time of the return value is a millisecond, * the granularity of the value depends on the underlying * operating system and may be larger. For example, many * operating systems measure time in units of tens of * milliseconds. * * <p> See the description of the class <code>Date</code> for * a discussion of slight discrepancies that may arise between * "computer time" and coordinated universal time (UTC). * * @return the difference, measured in milliseconds, between * the current time and midnight, January 1, 1970 UTC. * @see java.util.Date */ publicstaticnativelongcurrentTimeMillis();
/** * Returns the current value of the running Java Virtual Machine's * high-resolution time source, in nanoseconds. * * <p>This method can only be used to measure elapsed time and is * not related to any other notion of system or wall-clock time. * The value returned represents nanoseconds since some fixed but * arbitrary <i>origin</i> time (perhaps in the future, so values * may be negative). The same origin is used by all invocations of * this method in an instance of a Java virtual machine; other * virtual machine instances are likely to use a different origin. * * <p>This method provides nanosecond precision, but not necessarily * nanosecond resolution (that is, how frequently the value changes) * - no guarantees are made except that the resolution is at least as * good as that of {@link #currentTimeMillis()}. * * <p>Differences in successive calls that span greater than * approximately 292 years (2<sup>63</sup> nanoseconds) will not * correctly compute elapsed time due to numerical overflow. * * <p>The values returned by this method become meaningful only when * the difference between two such values, obtained within the same * instance of a Java virtual machine, is computed. * * <p> For example, to measure how long some code takes to execute: * <pre> {@code * long startTime = System.nanoTime(); * // ... the code being measured ... * long estimatedTime = System.nanoTime() - startTime;}</pre> * * <p>To compare two nanoTime values * <pre> {@code * long t0 = System.nanoTime(); * ... * long t1 = System.nanoTime();}</pre> * * one should use {@code t1 - t0 < 0}, not {@code t1 < t0}, * because of the possibility of numerical overflow. * * @return the current value of the running Java Virtual Machine's * high-resolution time source, in nanoseconds * @since 1.5 */ publicstaticnativelongnanoTime();
/** * Copies an array from the specified source array, beginning at the * specified position, to the specified position of the destination array. * A subsequence of array components are copied from the source * array referenced by <code>src</code> to the destination array * referenced by <code>dest</code>. The number of components copied is * equal to the <code>length</code> argument. The components at * positions <code>srcPos</code> through * <code>srcPos+length-1</code> in the source array are copied into * positions <code>destPos</code> through * <code>destPos+length-1</code>, respectively, of the destination * array. * <p> * If the <code>src</code> and <code>dest</code> arguments refer to the * same array object, then the copying is performed as if the * components at positions <code>srcPos</code> through * <code>srcPos+length-1</code> were first copied to a temporary * array with <code>length</code> components and then the contents of * the temporary array were copied into positions * <code>destPos</code> through <code>destPos+length-1</code> of the * destination array. * <p> * If <code>dest</code> is <code>null</code>, then a * <code>NullPointerException</code> is thrown. * <p> * If <code>src</code> is <code>null</code>, then a * <code>NullPointerException</code> is thrown and the destination * array is not modified. * <p> * Otherwise, if any of the following is true, an * <code>ArrayStoreException</code> is thrown and the destination is * not modified: * <ul> * <li>The <code>src</code> argument refers to an object that is not an * array. * <li>The <code>dest</code> argument refers to an object that is not an * array. * <li>The <code>src</code> argument and <code>dest</code> argument refer * to arrays whose component types are different primitive types. * <li>The <code>src</code> argument refers to an array with a primitive * component type and the <code>dest</code> argument refers to an array * with a reference component type. * <li>The <code>src</code> argument refers to an array with a reference * component type and the <code>dest</code> argument refers to an array * with a primitive component type. * </ul> * <p> * Otherwise, if any of the following is true, an * <code>IndexOutOfBoundsException</code> is * thrown and the destination is not modified: * <ul> * <li>The <code>srcPos</code> argument is negative. * <li>The <code>destPos</code> argument is negative. * <li>The <code>length</code> argument is negative. * <li><code>srcPos+length</code> is greater than * <code>src.length</code>, the length of the source array. * <li><code>destPos+length</code> is greater than * <code>dest.length</code>, the length of the destination array. * </ul> * <p> * Otherwise, if any actual component of the source array from * position <code>srcPos</code> through * <code>srcPos+length-1</code> cannot be converted to the component * type of the destination array by assignment conversion, an * <code>ArrayStoreException</code> is thrown. In this case, let * <b><i>k</i></b> be the smallest nonnegative integer less than * length such that <code>src[srcPos+</code><i>k</i><code>]</code> * cannot be converted to the component type of the destination * array; when the exception is thrown, source array components from * positions <code>srcPos</code> through * <code>srcPos+</code><i>k</i><code>-1</code> * will already have been copied to destination array positions * <code>destPos</code> through * <code>destPos+</code><i>k</I><code>-1</code> and no other * positions of the destination array will have been modified. * (Because of the restrictions already itemized, this * paragraph effectively applies only to the situation where both * arrays have component types that are reference types.) * * @param src the source array. * @param srcPos starting position in the source array. * @param dest the destination array. * @param destPos starting position in the destination data. * @param length the number of array elements to be copied. * @exception IndexOutOfBoundsException if copying would cause * access of data outside array bounds. * @exception ArrayStoreException if an element in the <code>src</code> * array could not be stored into the <code>dest</code> array * because of a type mismatch. * @exception NullPointerException if either <code>src</code> or * <code>dest</code> is <code>null</code>. */ publicstaticnativevoidarraycopy(Object src, int srcPos, Object dest, int destPos, int length);
/** * Returns the same hash code for the given object as * would be returned by the default method hashCode(), * whether or not the given object's class overrides * hashCode(). * The hash code for the null reference is zero. * * @param x object for which the hashCode is to be calculated * @return the hashCode * @since JDK1.1 */ publicstaticnativeintidentityHashCode(Object x);
/** * System properties. The following properties are guaranteed to be defined: * <dl> * <dt>java.version <dd>Java version number * <dt>java.vendor <dd>Java vendor specific string * <dt>java.vendor.url <dd>Java vendor URL * <dt>java.home <dd>Java installation directory * <dt>java.class.version <dd>Java class version number * <dt>java.class.path <dd>Java classpath * <dt>os.name <dd>Operating System Name * <dt>os.arch <dd>Operating System Architecture * <dt>os.version <dd>Operating System Version * <dt>file.separator <dd>File separator ("/" on Unix) * <dt>path.separator <dd>Path separator (":" on Unix) * <dt>line.separator <dd>Line separator ("\n" on Unix) * <dt>user.name <dd>User account name * <dt>user.home <dd>User home directory * <dt>user.dir <dd>User's current working directory * </dl> */
/** * Determines the current system properties. * <p> * First, if there is a security manager, its * <code>checkPropertiesAccess</code> method is called with no * arguments. This may result in a security exception. * <p> * The current set of system properties for use by the * {@link #getProperty(String)} method is returned as a * <code>Properties</code> object. If there is no current set of * system properties, a set of system properties is first created and * initialized. This set of system properties always includes values * for the following keys: * <table summary="Shows property keys and associated values"> * <tr><th>Key</th> * <th>Description of Associated Value</th></tr> * <tr><td><code>java.version</code></td> * <td>Java Runtime Environment version</td></tr> * <tr><td><code>java.vendor</code></td> * <td>Java Runtime Environment vendor</td></tr> * <tr><td><code>java.vendor.url</code></td> * <td>Java vendor URL</td></tr> * <tr><td><code>java.home</code></td> * <td>Java installation directory</td></tr> * <tr><td><code>java.vm.specification.version</code></td> * <td>Java Virtual Machine specification version</td></tr> * <tr><td><code>java.vm.specification.vendor</code></td> * <td>Java Virtual Machine specification vendor</td></tr> * <tr><td><code>java.vm.specification.name</code></td> * <td>Java Virtual Machine specification name</td></tr> * <tr><td><code>java.vm.version</code></td> * <td>Java Virtual Machine implementation version</td></tr> * <tr><td><code>java.vm.vendor</code></td> * <td>Java Virtual Machine implementation vendor</td></tr> * <tr><td><code>java.vm.name</code></td> * <td>Java Virtual Machine implementation name</td></tr> * <tr><td><code>java.specification.version</code></td> * <td>Java Runtime Environment specification version</td></tr> * <tr><td><code>java.specification.vendor</code></td> * <td>Java Runtime Environment specification vendor</td></tr> * <tr><td><code>java.specification.name</code></td> * <td>Java Runtime Environment specification name</td></tr> * <tr><td><code>java.class.version</code></td> * <td>Java class format version number</td></tr> * <tr><td><code>java.class.path</code></td> * <td>Java class path</td></tr> * <tr><td><code>java.library.path</code></td> * <td>List of paths to search when loading libraries</td></tr> * <tr><td><code>java.io.tmpdir</code></td> * <td>Default temp file path</td></tr> * <tr><td><code>java.compiler</code></td> * <td>Name of JIT compiler to use</td></tr> * <tr><td><code>java.ext.dirs</code></td> * <td>Path of extension directory or directories * <b>Deprecated.</b> <i>This property, and the mechanism * which implements it, may be removed in a future * release.</i> </td></tr> * <tr><td><code>os.name</code></td> * <td>Operating system name</td></tr> * <tr><td><code>os.arch</code></td> * <td>Operating system architecture</td></tr> * <tr><td><code>os.version</code></td> * <td>Operating system version</td></tr> * <tr><td><code>file.separator</code></td> * <td>File separator ("/" on UNIX)</td></tr> * <tr><td><code>path.separator</code></td> * <td>Path separator (":" on UNIX)</td></tr> * <tr><td><code>line.separator</code></td> * <td>Line separator ("\n" on UNIX)</td></tr> * <tr><td><code>user.name</code></td> * <td>User's account name</td></tr> * <tr><td><code>user.home</code></td> * <td>User's home directory</td></tr> * <tr><td><code>user.dir</code></td> * <td>User's current working directory</td></tr> * </table> * <p> * Multiple paths in a system property value are separated by the path * separator character of the platform. * <p> * Note that even if the security manager does not permit the * <code>getProperties</code> operation, it may choose to permit the * {@link #getProperty(String)} operation. * * @return the system properties * @exception SecurityException if a security manager exists and its * <code>checkPropertiesAccess</code> method doesn't allow access * to the system properties. * @see #setProperties * @see java.lang.SecurityException * @see java.lang.SecurityManager#checkPropertiesAccess() * @see java.util.Properties */ publicstatic Properties getProperties(){ SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPropertiesAccess(); }
return props; }
/** * Returns the system-dependent line separator string. It always * returns the same value - the initial value of the {@linkplain * #getProperty(String) system property} {@code line.separator}. * * <p>On UNIX systems, it returns {@code "\n"}; on Microsoft * Windows systems it returns {@code "\r\n"}. * * @return the system-dependent line separator string * @since 1.7 */ publicstatic String lineSeparator(){ return lineSeparator; }
privatestatic String lineSeparator;
/** * Sets the system properties to the <code>Properties</code> * argument. * <p> * First, if there is a security manager, its * <code>checkPropertiesAccess</code> method is called with no * arguments. This may result in a security exception. * <p> * The argument becomes the current set of system properties for use * by the {@link #getProperty(String)} method. If the argument is * <code>null</code>, then the current set of system properties is * forgotten. * * @param props the new system properties. * @exception SecurityException if a security manager exists and its * <code>checkPropertiesAccess</code> method doesn't allow access * to the system properties. * @see #getProperties * @see java.util.Properties * @see java.lang.SecurityException * @see java.lang.SecurityManager#checkPropertiesAccess() */ publicstaticvoidsetProperties(Properties props){ SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPropertiesAccess(); } if (props == null) { props = new Properties(); initProperties(props); } System.props = props; }
/** * Gets the system property indicated by the specified key. * <p> * First, if there is a security manager, its * <code>checkPropertyAccess</code> method is called with the key as * its argument. This may result in a SecurityException. * <p> * If there is no current set of system properties, a set of system * properties is first created and initialized in the same manner as * for the <code>getProperties</code> method. * * @param key the name of the system property. * @return the string value of the system property, * or <code>null</code> if there is no property with that key. * * @exception SecurityException if a security manager exists and its * <code>checkPropertyAccess</code> method doesn't allow * access to the specified system property. * @exception NullPointerException if <code>key</code> is * <code>null</code>. * @exception IllegalArgumentException if <code>key</code> is empty. * @see #setProperty * @see java.lang.SecurityException * @see java.lang.SecurityManager#checkPropertyAccess(java.lang.String) * @see java.lang.System#getProperties() */ publicstatic String getProperty(String key){ checkKey(key); SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPropertyAccess(key); }
return props.getProperty(key); }
/** * Gets the system property indicated by the specified key. * <p> * First, if there is a security manager, its * <code>checkPropertyAccess</code> method is called with the * <code>key</code> as its argument. * <p> * If there is no current set of system properties, a set of system * properties is first created and initialized in the same manner as * for the <code>getProperties</code> method. * * @param key the name of the system property. * @param def a default value. * @return the string value of the system property, * or the default value if there is no property with that key. * * @exception SecurityException if a security manager exists and its * <code>checkPropertyAccess</code> method doesn't allow * access to the specified system property. * @exception NullPointerException if <code>key</code> is * <code>null</code>. * @exception IllegalArgumentException if <code>key</code> is empty. * @see #setProperty * @see java.lang.SecurityManager#checkPropertyAccess(java.lang.String) * @see java.lang.System#getProperties() */ publicstatic String getProperty(String key, String def){ checkKey(key); SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPropertyAccess(key); }
return props.getProperty(key, def); }
/** * Sets the system property indicated by the specified key. * <p> * First, if a security manager exists, its * <code>SecurityManager.checkPermission</code> method * is called with a <code>PropertyPermission(key, "write")</code> * permission. This may result in a SecurityException being thrown. * If no exception is thrown, the specified property is set to the given * value. * <p> * * @param key the name of the system property. * @param value the value of the system property. * @return the previous value of the system property, * or <code>null</code> if it did not have one. * * @exception SecurityException if a security manager exists and its * <code>checkPermission</code> method doesn't allow * setting of the specified property. * @exception NullPointerException if <code>key</code> or * <code>value</code> is <code>null</code>. * @exception IllegalArgumentException if <code>key</code> is empty. * @see #getProperty * @see java.lang.System#getProperty(java.lang.String) * @see java.lang.System#getProperty(java.lang.String, java.lang.String) * @see java.util.PropertyPermission * @see SecurityManager#checkPermission * @since 1.2 */ publicstatic String setProperty(String key, String value){ checkKey(key); SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPermission(new PropertyPermission(key, SecurityConstants.PROPERTY_WRITE_ACTION)); }
return (String) props.setProperty(key, value); }
/** * Removes the system property indicated by the specified key. * <p> * First, if a security manager exists, its * <code>SecurityManager.checkPermission</code> method * is called with a <code>PropertyPermission(key, "write")</code> * permission. This may result in a SecurityException being thrown. * If no exception is thrown, the specified property is removed. * <p> * * @param key the name of the system property to be removed. * @return the previous string value of the system property, * or <code>null</code> if there was no property with that key. * * @exception SecurityException if a security manager exists and its * <code>checkPropertyAccess</code> method doesn't allow * access to the specified system property. * @exception NullPointerException if <code>key</code> is * <code>null</code>. * @exception IllegalArgumentException if <code>key</code> is empty. * @see #getProperty * @see #setProperty * @see java.util.Properties * @see java.lang.SecurityException * @see java.lang.SecurityManager#checkPropertiesAccess() * @since 1.5 */ publicstatic String clearProperty(String key){ checkKey(key); SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPermission(new PropertyPermission(key, "write")); }
return (String) props.remove(key); }
privatestaticvoidcheckKey(String key){ if (key == null) { thrownew NullPointerException("key can't be null"); } if (key.equals("")) { thrownew IllegalArgumentException("key can't be empty"); } }
/** * Gets the value of the specified environment variable. An * environment variable is a system-dependent external named * value. * * <p>If a security manager exists, its * {@link SecurityManager#checkPermission checkPermission} * method is called with a * <code>{@link RuntimePermission}("getenv."+name)</code> * permission. This may result in a {@link SecurityException} * being thrown. If no exception is thrown the value of the * variable <code>name</code> is returned. * * <p><a name="EnvironmentVSSystemProperties"><i>System * properties</i> and <i>environment variables</i></a> are both * conceptually mappings between names and values. Both * mechanisms can be used to pass user-defined information to a * Java process. Environment variables have a more global effect, * because they are visible to all descendants of the process * which defines them, not just the immediate Java subprocess. * They can have subtly different semantics, such as case * insensitivity, on different operating systems. For these * reasons, environment variables are more likely to have * unintended side effects. It is best to use system properties * where possible. Environment variables should be used when a * global effect is desired, or when an external system interface * requires an environment variable (such as <code>PATH</code>). * * <p>On UNIX systems the alphabetic case of <code>name</code> is * typically significant, while on Microsoft Windows systems it is * typically not. For example, the expression * <code>System.getenv("FOO").equals(System.getenv("foo"))</code> * is likely to be true on Microsoft Windows. * * @param name the name of the environment variable * @return the string value of the variable, or <code>null</code> * if the variable is not defined in the system environment * @throws NullPointerException if <code>name</code> is <code>null</code> * @throws SecurityException * if a security manager exists and its * {@link SecurityManager#checkPermission checkPermission} * method doesn't allow access to the environment variable * <code>name</code> * @see #getenv() * @see ProcessBuilder#environment() */ publicstatic String getenv(String name){ SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPermission(new RuntimePermission("getenv."+name)); }
return ProcessEnvironment.getenv(name); }
/** * Returns an unmodifiable string map view of the current system environment. * The environment is a system-dependent mapping from names to * values which is passed from parent to child processes. * * <p>If the system does not support environment variables, an * empty map is returned. * * <p>The returned map will never contain null keys or values. * Attempting to query the presence of a null key or value will * throw a {@link NullPointerException}. Attempting to query * the presence of a key or value which is not of type * {@link String} will throw a {@link ClassCastException}. * * <p>The returned map and its collection views may not obey the * general contract of the {@link Object#equals} and * {@link Object#hashCode} methods. * * <p>The returned map is typically case-sensitive on all platforms. * * <p>If a security manager exists, its * {@link SecurityManager#checkPermission checkPermission} * method is called with a * <code>{@link RuntimePermission}("getenv.*")</code> * permission. This may result in a {@link SecurityException} being * thrown. * * <p>When passing information to a Java subprocess, * <a href=#EnvironmentVSSystemProperties>system properties</a> * are generally preferred over environment variables. * * @return the environment as a map of variable names to values * @throws SecurityException * if a security manager exists and its * {@link SecurityManager#checkPermission checkPermission} * method doesn't allow access to the process environment * @see #getenv(String) * @see ProcessBuilder#environment() * @since 1.5 */ publicstatic java.util.Map<String,String> getenv(){ SecurityManager sm = getSecurityManager(); if (sm != null) { sm.checkPermission(new RuntimePermission("getenv.*")); }
return ProcessEnvironment.getenv(); }
/** * Terminates the currently running Java Virtual Machine. The * argument serves as a status code; by convention, a nonzero status * code indicates abnormal termination. * <p> * This method calls the <code>exit</code> method in class * <code>Runtime</code>. This method never returns normally. * <p> * The call <code>System.exit(n)</code> is effectively equivalent to * the call: * <blockquote><pre> * Runtime.getRuntime().exit(n) * </pre></blockquote> * * @param status exit status. * @throws SecurityException * if a security manager exists and its <code>checkExit</code> * method doesn't allow exit with the specified status. * @see java.lang.Runtime#exit(int) */ publicstaticvoidexit(int status){ Runtime.getRuntime().exit(status); }
/** * Runs the garbage collector. * <p> * Calling the <code>gc</code> method suggests that the Java Virtual * Machine expend effort toward recycling unused objects in order to * make the memory they currently occupy available for quick reuse. * When control returns from the method call, the Java Virtual * Machine has made a best effort to reclaim space from all discarded * objects. * <p> * The call <code>System.gc()</code> is effectively equivalent to the * call: * <blockquote><pre> * Runtime.getRuntime().gc() * </pre></blockquote> * * @see java.lang.Runtime#gc() */ publicstaticvoidgc(){ Runtime.getRuntime().gc(); }
/** * Runs the finalization methods of any objects pending finalization. * <p> * Calling this method suggests that the Java Virtual Machine expend * effort toward running the <code>finalize</code> methods of objects * that have been found to be discarded but whose <code>finalize</code> * methods have not yet been run. When control returns from the * method call, the Java Virtual Machine has made a best effort to * complete all outstanding finalizations. * <p> * The call <code>System.runFinalization()</code> is effectively * equivalent to the call: * <blockquote><pre> * Runtime.getRuntime().runFinalization() * </pre></blockquote> * * @see java.lang.Runtime#runFinalization() */ publicstaticvoidrunFinalization(){ Runtime.getRuntime().runFinalization(); }
/** * Enable or disable finalization on exit; doing so specifies that the * finalizers of all objects that have finalizers that have not yet been * automatically invoked are to be run before the Java runtime exits. * By default, finalization on exit is disabled. * * <p>If there is a security manager, * its <code>checkExit</code> method is first called * with 0 as its argument to ensure the exit is allowed. * This could result in a SecurityException. * * @deprecated This method is inherently unsafe. It may result in * finalizers being called on live objects while other threads are * concurrently manipulating those objects, resulting in erratic * behavior or deadlock. * @param value indicating enabling or disabling of finalization * @throws SecurityException * if a security manager exists and its <code>checkExit</code> * method doesn't allow the exit. * * @see java.lang.Runtime#exit(int) * @see java.lang.Runtime#gc() * @see java.lang.SecurityManager#checkExit(int) * @since JDK1.1 */ @Deprecated publicstaticvoidrunFinalizersOnExit(boolean value){ Runtime.runFinalizersOnExit(value); }
/** * Loads the native library specified by the filename argument. The filename * argument must be an absolute path name. * * If the filename argument, when stripped of any platform-specific library * prefix, path, and file extension, indicates a library whose name is, * for example, L, and a native library called L is statically linked * with the VM, then the JNI_OnLoad_L function exported by the library * is invoked rather than attempting to load a dynamic library. * A filename matching the argument does not have to exist in the * file system. * See the JNI Specification for more details. * * Otherwise, the filename argument is mapped to a native library image in * an implementation-dependent manner. * * <p> * The call <code>System.load(name)</code> is effectively equivalent * to the call: * <blockquote><pre> * Runtime.getRuntime().load(name) * </pre></blockquote> * * @param filename the file to load. * @exception SecurityException if a security manager exists and its * <code>checkLink</code> method doesn't allow * loading of the specified dynamic library * @exception UnsatisfiedLinkError if either the filename is not an * absolute path name, the native library is not statically * linked with the VM, or the library cannot be mapped to * a native library image by the host system. * @exception NullPointerException if <code>filename</code> is * <code>null</code> * @see java.lang.Runtime#load(java.lang.String) * @see java.lang.SecurityManager#checkLink(java.lang.String) */ @CallerSensitive publicstaticvoidload(String filename){ Runtime.getRuntime().load0(Reflection.getCallerClass(), filename); }
/** * Loads the native library specified by the <code>libname</code> * argument. The <code>libname</code> argument must not contain any platform * specific prefix, file extension or path. If a native library * called <code>libname</code> is statically linked with the VM, then the * JNI_OnLoad_<code>libname</code> function exported by the library is invoked. * See the JNI Specification for more details. * * Otherwise, the libname argument is loaded from a system library * location and mapped to a native library image in an implementation- * dependent manner. * <p> * The call <code>System.loadLibrary(name)</code> is effectively * equivalent to the call * <blockquote><pre> * Runtime.getRuntime().loadLibrary(name) * </pre></blockquote> * * @param libname the name of the library. * @exception SecurityException if a security manager exists and its * <code>checkLink</code> method doesn't allow * loading of the specified dynamic library * @exception UnsatisfiedLinkError if either the libname argument * contains a file path, the native library is not statically * linked with the VM, or the library cannot be mapped to a * native library image by the host system. * @exception NullPointerException if <code>libname</code> is * <code>null</code> * @see java.lang.Runtime#loadLibrary(java.lang.String) * @see java.lang.SecurityManager#checkLink(java.lang.String) */ @CallerSensitive publicstaticvoidloadLibrary(String libname){ Runtime.getRuntime().loadLibrary0(Reflection.getCallerClass(), libname); }
/** * Maps a library name into a platform-specific string representing * a native library. * * @param libname the name of the library. * @return a platform-dependent native library name. * @exception NullPointerException if <code>libname</code> is * <code>null</code> * @see java.lang.System#loadLibrary(java.lang.String) * @see java.lang.ClassLoader#findLibrary(java.lang.String) * @since 1.2 */ publicstaticnative String mapLibraryName(String libname);
/** * Initialize the system class. Called after thread initialization. */ privatestaticvoidinitializeSystemClass(){
// VM might invoke JNU_NewStringPlatform() to set those encoding // sensitive properties (user.home, user.name, boot.class.path, etc.) // during "props" initialization, in which it may need access, via // System.getProperty(), to the related system encoding property that // have been initialized (put into "props") at early stage of the // initialization. So make sure the "props" is available at the // very beginning of the initialization and all system properties to // be put into it directly. props = new Properties(); initProperties(props); // initialized by the VM
// There are certain system configurations that may be controlled by // VM options such as the maximum amount of direct memory and // Integer cache size used to support the object identity semantics // of autoboxing. Typically, the library will obtain these values // from the properties set by the VM. If the properties are for // internal implementation use only, these properties should be // removed from the system properties. // // See java.lang.Integer.IntegerCache and the // sun.misc.VM.saveAndRemoveProperties method for example. // // Save a private copy of the system properties object that // can only be accessed by the internal implementation. Remove // certain system properties that are not intended for public access. sun.misc.VM.saveAndRemoveProperties(props);
FileInputStream fdIn = new FileInputStream(FileDescriptor.in); FileOutputStream fdOut = new FileOutputStream(FileDescriptor.out); FileOutputStream fdErr = new FileOutputStream(FileDescriptor.err); setIn0(new BufferedInputStream(fdIn)); setOut0(newPrintStream(fdOut, props.getProperty("sun.stdout.encoding"))); setErr0(newPrintStream(fdErr, props.getProperty("sun.stderr.encoding")));
// Load the zip library now in order to keep java.util.zip.ZipFile // from trying to use itself to load this library later. loadLibrary("zip");
// Setup Java signal handlers for HUP, TERM, and INT (where available). Terminator.setup();
// Initialize any miscellenous operating system settings that need to be // set for the class libraries. Currently this is no-op everywhere except // for Windows where the process-wide error mode is set before the java.io // classes are used. sun.misc.VM.initializeOSEnvironment();
// The main thread is not added to its thread group in the same // way as other threads; we must do it ourselves here. Thread current = Thread.currentThread(); current.getThreadGroup().add(current);
// register shared secrets setJavaLangAccess();
// Subsystems that are invoked during initialization can invoke // sun.misc.VM.isBooted() in order to avoid doing things that should // wait until the application class loader has been set up. // IMPORTANT: Ensure that this remains the last initialization action! sun.misc.VM.booted(); }