TensorFlow 2.0 中文手写字识别(汉字OCR)
- 搜索空间空前巨大,我们使用的数据集1.0版本汉字就多大3755个,如果加上1.1版本一起,总共汉字可以分为多达7599+个类别!这比10个阿拉伯字母识别难度大很多!
- 数据集处理挑战更大,相比于mnist和fasionmnist来说,汉字手写字体识别数据集非常少,而且仅有的数据集数据预处理难度非常大,非常不直观,但是,千万别吓到,相信你看完本教程一定会收货满满!
- 汉字识别更考验选手的建模能力,还在分类花?分类猫和狗?随便搭建的几层在搜索空间巨大的汉字手写识别里根本不work!你现在是不是想用很深的网络跃跃欲试?更深的网络在这个任务上可能根本不可行!!看完本教程我们就可以一探究竟!总之一句话,模型太简单和太复杂都不好,甚至会发散!(想亲身体验模型训练发散抓狂的可以来尝试一下!)。
数据准备
在开始之前,先介绍一下本项目所采用的数据信息。我们的数据全部来自于CASIA的开源中文手写字数据集,该数据集分为两部分:
- CASIA-HWDB:离线的HWDB,我们仅仅使用1.0-1.2,这是单字的数据集,2.0-2.2是整张文本的数据集,我们暂时不用,单字里面包含了约7185个汉字以及171个英文字母、数字、标点符号等;
- CASIA-OLHWDB:在线的HWDB,格式一样,包含了约7185个汉字以及171个英文字母、数字、标点符号等,我们不用。
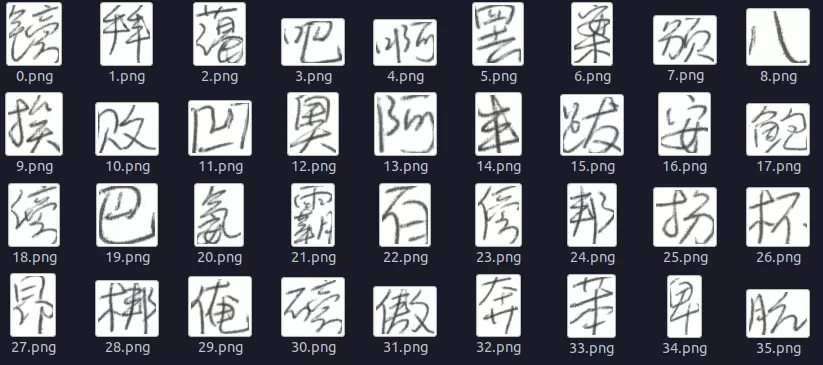
其实你下载1.0的train和test差不多已经够了,可以直接运行 dataset/get_hwdb_1.0_1.1.sh 下载。原始数据下载链接点击这里. 由于原始数据过于复杂,我们使用一个类来封装数据读取过程,这是我们展示的效果:

看到这么密密麻麻的文字相信连人类都…. 开始头疼了,这些复杂的文字能够通过一个神经网络来识别出来??答案是肯定的…. 不有得感叹一下神经网络的强大。。上面的部分文字识别出来的结果是这样的:

关于数据的处理部分,从服务器下载到的原始数据是 trn_gnt.zip 解压之后是 gnt.alz, 需要再次解压得到一个包含 gnt文件的文件夹。里面每一个gnt文件都包含了若干个汉字及其标注。直接处理比较麻烦,也不方便抽取出图片再进行操作,虽然转为图片存入文件夹比较直观,但是不适合批量读取和训练, 后面我们统一转为tfrecord进行训练。
更新: 实际上,由于单个汉字图片其实很小,差不多也就最大80x80的大小,这个大小不适合转成图片保存到本地,因此我们将hwdb原始的二进制保存为tfrecord。同时也方便后面训练,可以直接从tfrecord读取图片进行训练。
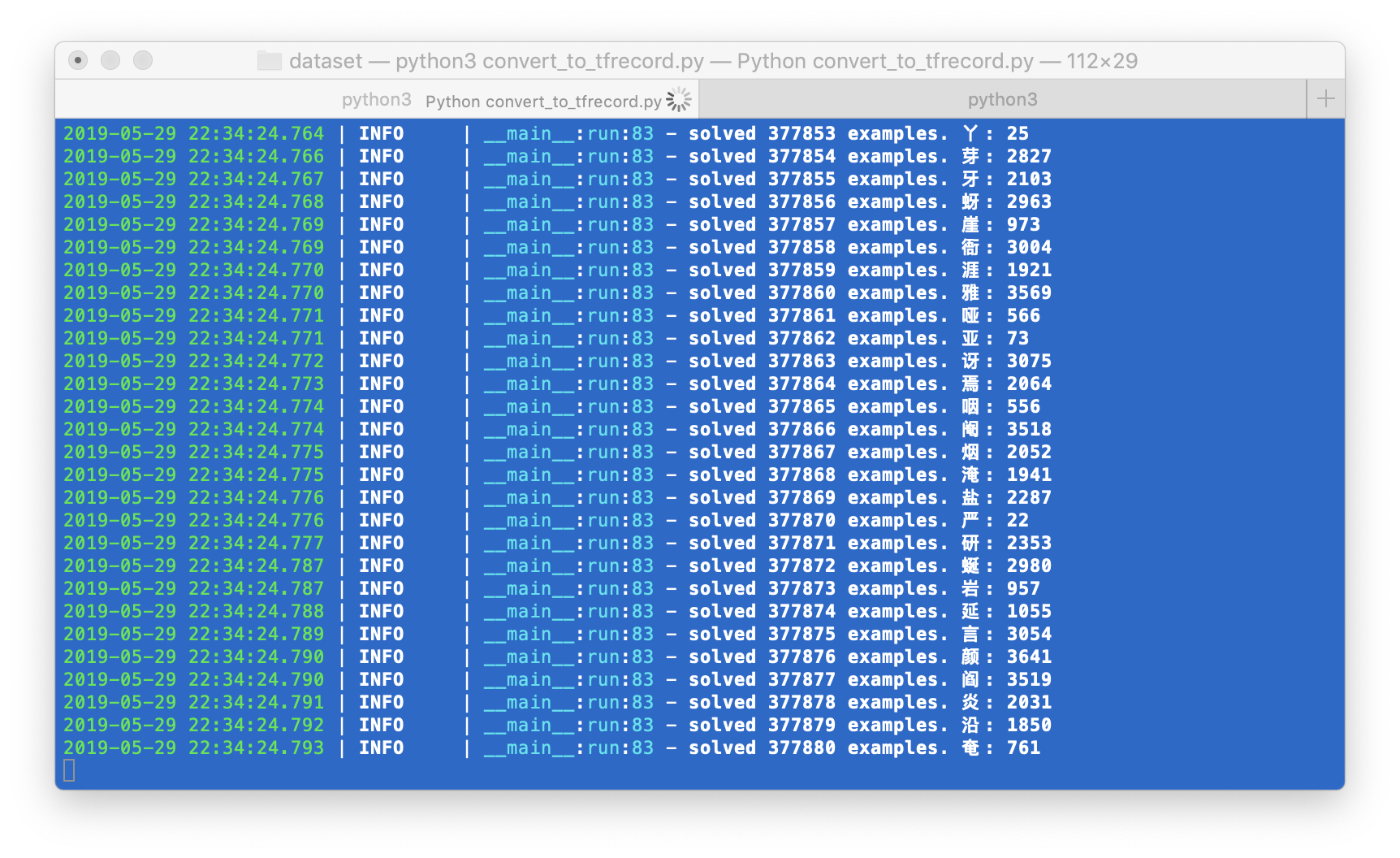
训练过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| def train():
all_characters = load_characters()
num_classes = len(all_characters)
logging.info('all characters: {}'.format(num_classes))
train_dataset = load_ds()
train_dataset = train_dataset.shuffle(100).map(preprocess).batch(32).repeat()
val_ds = load_val_ds()
val_ds = val_ds.shuffle(100).map(preprocess).batch(32).repeat()
for data in train_dataset.take(2):
print(data)
model = build_net_003((64, 64, 1), num_classes)
model.summary()
logging.info('model loaded.')
start_epoch = 0
latest_ckpt = tf.train.latest_checkpoint(os.path.dirname(ckpt_path))
if latest_ckpt:
start_epoch = int(latest_ckpt.split('-')[1].split('.')[0])
model.load_weights(latest_ckpt)
logging.info('model resumed from: {}, start at epoch: {}'.format(latest_ckpt, start_epoch))
else:
logging.info('passing resume since weights not there. training from scratch')
if use_keras_fit:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
callbacks = [
tf.keras.callbacks.ModelCheckpoint(ckpt_path,
save_weights_only=True,
verbose=1,
period=500)
]
try:
model.fit(
train_dataset,
validation_data=val_ds,
validation_steps=1000,
epochs=15000,
steps_per_epoch=1024,
callbacks=callbacks)
except KeyboardInterrupt:
model.save_weights(ckpt_path.format(epoch=0))
logging.info('keras model saved.')
model.save_weights(ckpt_path.format(epoch=0))
model.save(os.path.join(os.path.dirname(ckpt_path), 'cn_ocr.h5'))
|
大家在以后编写训练代码的时候其实可以保持这个好的习惯。
OK,整个模型训练起来之后,可以在短时间内达到95%的准确率:
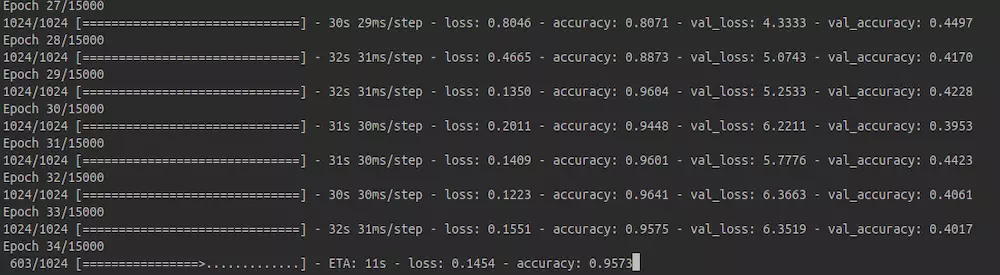
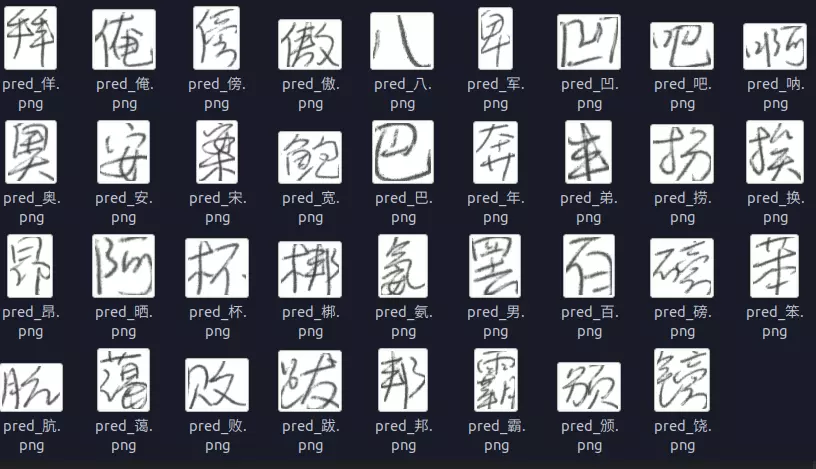
总结
通过本教程,我们完成了使用tensorflow 2.0全新的API搭建一个中文汉字手写识别系统。模型基本能够实现我们想要的功能。要知道,这个模型可是在搜索空间多大3755的类别当中准确的找到最相似的类别!!通过本实验,我们有几点心得:
- 神经网络不仅仅是在学习,它具有一定的想象力!!比如它的一些看着很像的字:拜-佯, 扮-捞,笨-苯…. 这些字如果手写出来,连人都比较难以辨认!!但是大家要知道这些字在类别上并不是相领的!也就是说,模型具有一定的联想能力!
- 不管问题多复杂,要敢于动手、善于动手。