PaddlePaddle Models
![]()
![]()
PaddlePaddle 提供了丰富的计算单元,使得用户可以采用模块化的方法解决各种学习问题。在此Repo中,我们展示了如何用 PaddlePaddle来解决常见的机器学习任务,提供若干种不同的易学易用的神经网络模型。PaddlePaddle用户可领取免费Tesla V100在线算力资源,高效训练模型,每日登陆即送12小时,连续五天运行再加送48小时,前往使用免费算力。

![]()
![]()
PaddlePaddle 提供了丰富的计算单元,使得用户可以采用模块化的方法解决各种学习问题。在此Repo中,我们展示了如何用 PaddlePaddle来解决常见的机器学习任务,提供若干种不同的易学易用的神经网络模型。PaddlePaddle用户可领取免费Tesla V100在线算力资源,高效训练模型,每日登陆即送12小时,连续五天运行再加送48小时,前往使用免费算力。
Contributed by Xiaozhi Wang and Zhengyan Zhang.
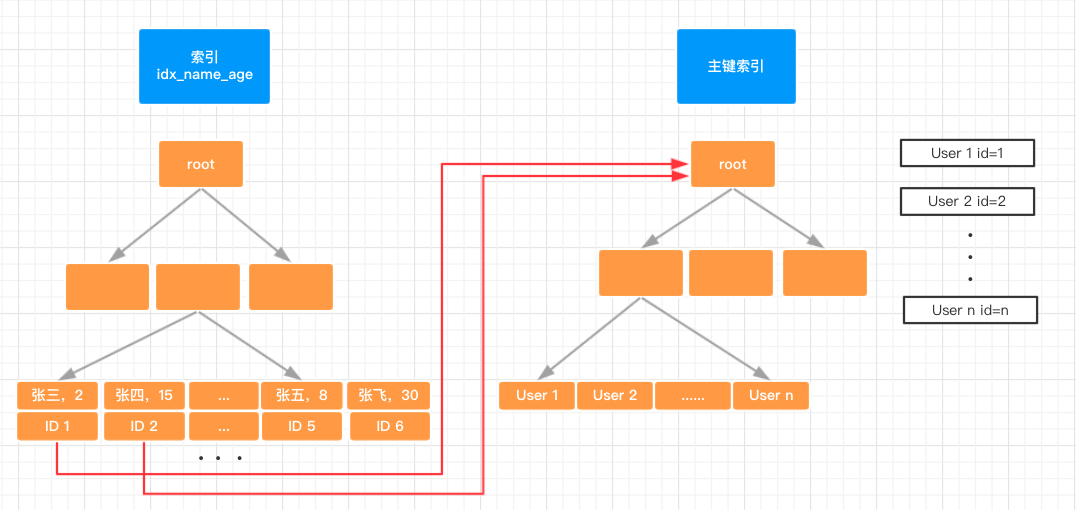
Pre-trained Languge Model (PLM) is a very popular topic in NLP. In this repo, we list some representative work on PLM and show their relationship with a diagram. Feel free to distribute or use it! Here you can get the source PPT file of the diagram if you want to use it in your presentation.
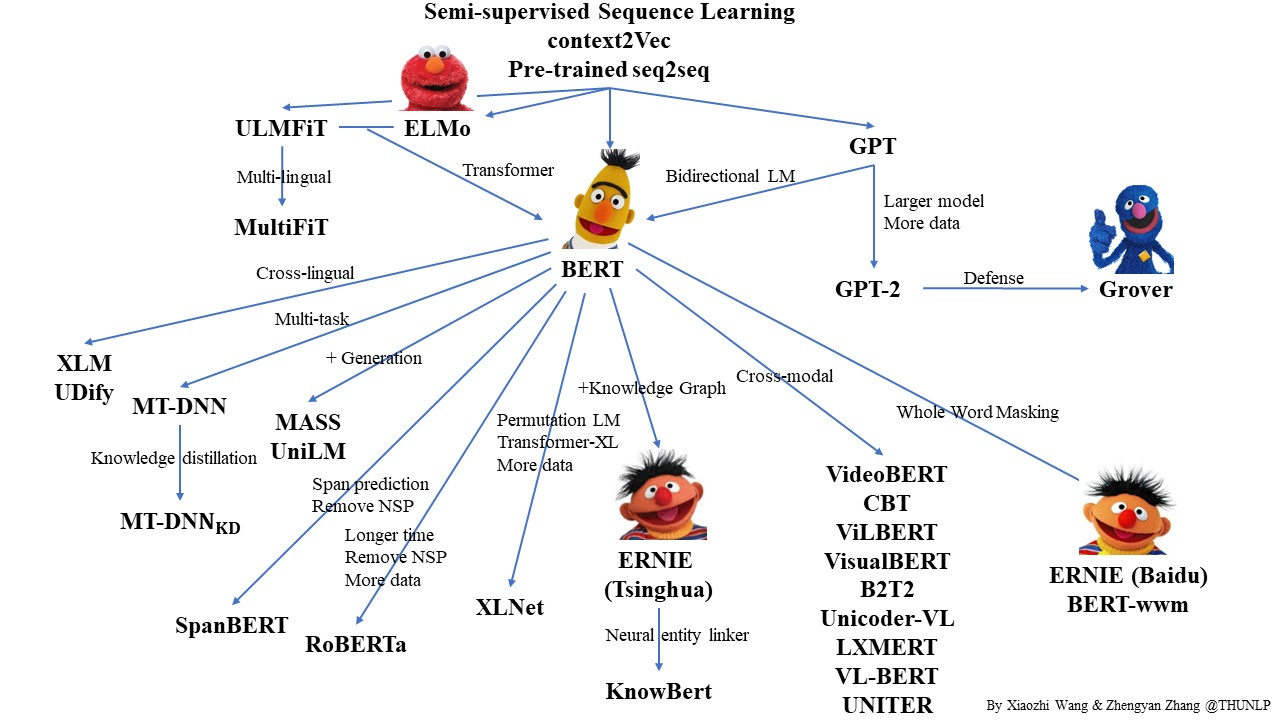
Corrections and suggestions are welcomed.
We also released OpenCLap, an open-source Chinese language pre-trained model zoo. Welcome to try it.
自语言处理然(英语:Natural Language Processing,缩写作 NLP)是人工智能和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。
自然语言认知和理解是让计算机把输入的语言变成有意思的符号和关系,然后根据目的再处理。自然语言生成系统则是把计算机数据转化为自然语言。
自然语言处理大体是从1950年代开始,虽然更早期也有作为。1950年,图灵发表论文“计算机器与智能”,提出现在所谓的“图灵测试”作为判断智能的条件。
1954年的乔治城实验涉及全部自动翻译超过60句俄文成为英文。研究人员声称三到五年之内即可解决机器翻译的问题。[1]不过实际进展远低于预期,1966年的ALPAC报告发现十年研究未达预期目标,机器翻译的研究经费遭到大幅削减。一直到1980年代末期,统计机器翻译系统发展出来,机器翻译的研究才得以更上一层楼。
1960年代发展特别成功的NLP系统包括SHRDLU——一个词汇设限、运作于受限如“积木世界”的一种自然语言系统,以及1964-1966年约瑟夫·维森鲍姆模拟“个人中心治疗”而设计的ELIZA——几乎未运用人类思想和感情的消息,有时候却能呈现令人讶异地类似人之间的交互。“病人”提出的问题超出ELIZA 极小的知识范围之时,可能会得到空泛的回答。例如问题是“我的头痛”,回答是“为什么说你头痛?”
1970年代,程序员开始设计“概念本体论”(conceptual ontologies)的程序,将现实世界的信息,架构成计算机能够理解的数据。实例有MARGIE、SAM、PAM、TaleSpin、QUALM、Politics以及Plot Unit。许多聊天机器人在这一时期写成,包括PARRY 、Racter 以及Jabberwacky 。
一直到1980年代,多数自然语言处理系统是以一套复杂、人工订定的规则为基础。不过从1980年代末期开始,语言处理引进了机器学习的算法,NLP产生革新。成因有两个:运算能力稳定增加(参见摩尔定律);以及乔姆斯基 语言学理论渐渐丧失主导(例如转换-生成文法)。该理论的架构不倾向于语料库——机器学习处理语言所用方法的基础。有些最早期使用的机器学习算法,例如决策树,是硬性的、“如果-则”规则组成的系统,类似当时既有的人工订定的规则。不过词性标记将隐马尔可夫模型引入NLP,并且研究日益聚焦于软性的、以几率做决定的统计模型,基础是将输入数据里每一个特性赋予代表其分量的数值。许多语音识别现今依赖的缓存语言模型即是一种统计模型的例子。这种模型通常足以处理非预期的输入数据,尤其是输入有错误(真实世界的数据总免不了),并且在集成到包含多个子任务的较大系统时,结果比较可靠。
许多早期的成功属于机器翻译领域,尤其归功IBM的研究,渐次发展出更复杂的统计模型。这些系统得以利用加拿大和欧盟现有的语料库,因为其法律规定政府的会议必须翻译成所有的官方语言。不过,其他大部分系统必须特别打造自己的语料库,一直到现在这都是限制其成功的一个主要因素,于是大量的研究致力于从有限的数据更有效地学习。
近来的研究更加聚焦于非监督式学习和半监督学习的算法。这种算法,能够从没有人工注解理想答案的数据里学习。大体而言,这种学习比监督学习困难,并且在同量的数据下,通常产生的结果较不准确。不过没有注解的数据量极巨(包含了万维网),弥补了较不准确的缺点。
近年来, 深度学习技巧纷纷出炉[2][3] 在自然语言处理方面获得最尖端的成果,例如语言模型[4]、语法分析[5][6]等等。
Update your browser to view this website correctly. Update my browser now