OpenCV边缘检测

1 | import cv2 |
1 | import cv2 |
不可以,因为String类有final修饰符,而final修饰的类是不能被继承的,实现细节不允许改变。
1 | public final class String implements java.io.Serializable, Comparable<String>, CharSequence |
根据程序上下文环境,Java关键字final有“这是无法改变的”或者“终态的”含义,它可以修饰非抽象类、非抽象类成员方法和变量。你可能出于两种理解而需要阻止改变:设计或效率。
final类不能被继承,没有子类,final类中的方法默认是final的。
final方法不能被子类的方法覆盖,但可以被继承。
final成员变量表示常量,只能被赋值一次,赋值后值不再改变。
final不能用于修饰构造方法。
注意:父类的private成员方法是不能被子类方法覆盖的,因此private类型的方法默认是final类型的。
如果一个类不允许其子类覆盖某个方法,则可以把这个方法声明为final方法。
使用final方法的原因有二:
第一、把方法锁定,防止任何继承类修改它的意义和实现。
第二、高效。编译器在遇到调用final方法时候会转入内嵌机制,大大提高执行效率。(这点有待商榷,《Java编程思想》中对于这点存疑)
下面这段话摘自《Java编程思想》第四版第143页:
“使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的Java版本中,不需要使用final方法进行这些优化了。”
关于String类,要了解常量池的概念
1 | String s = new String(“xyz”); //创建了几个对象 |
答案: 1个或2个, 如果”xyz”已经存在于常量池中,则只在堆中创建”xyz”对象的一个拷贝,否则还要在常量池中在创建一份
1 | String s = "a"+"b"+"c"+"d"; //创建了几个对象 |
答案: 这个和JVM实现有关, 如果常量池为空,可能是1个也可能是7个等
1、用来处理字符串常用的类有3种:String、StringBuffer和StringBuilder
2、三者之间的区别:
都是final类,都不允许被继承;
String类长度是不可变的,StringBuffer和StringBuilder类长度是可以改变的;
StringBuffer类是线程安全的,StringBuilder不是线程安全的;
String 和 StringBuffer:
1、String类型和StringBuffer类型的主要性能区别:String是不可变的对象,因此每次在对String类进行改变的时候都会生成一个新的string对象,然后将指针指向新的string对象,所以经常要改变字符串长度的话不要使用string,因为每次生成对象都会对系统性能产生影响,特别是当内存中引用的对象多了以后,JVM的GC就会开始工作,性能就会降低;
2、使用StringBuffer类时,每次都会对StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用,所以多数情况下推荐使用StringBuffer,特别是字符串对象经常要改变的情况;
3、在某些情况下,String对象的字符串拼接其实是被Java Compiler编译成了StringBuffer对象的拼接,所以这些时候String对象的速度并不会比StringBuffer对象慢,例如:
1 | String s1 = “This is only a” + “ simple” + “ test”; |
生成 String s1对象的速度并不比 StringBuffer慢。其实在Java Compiler里,自动做了如下转换:
1 | Java Compiler直接把上述第一条语句编译为: |
ArrayList是实现了基于动态数组的结构,LinkedList则是基于实现链表的数据结构。
数据的更新和查找
ArrayList的所有数据是在同一个地址上,而LinkedList的每个数据都拥有自己的地址.所以在对数据进行查找的时候,由于LinkedList的每个数据地址不一样,get数据的时候ArrayList的速度会优于LinkedList,而更新数据的时候,虽然都是通过循环循环到指定节点修改数据,但LinkedList的查询速度已经是慢的,而且对于LinkedList而言,更新数据时不像ArrayList只需要找到对应下标更新就好,LinkedList需要修改指针,速率不言而喻
数据的增加和删除
对于数据的增加元素,ArrayList是通过移动该元素之后的元素位置,其后元素位置全部+1,所以耗时较长,而LinkedList只需要将该元素前的后续指针指向该元素并将该元素的后续指针指向之后的元素即可。与增加相同,删除元素时ArrayList需要将被删除元素之后的元素位置-1,而LinkedList只需要将之后的元素前置指针指向前一元素,前一元素的指针指向后一元素即可。当然,事实上,若是单一元素的增删,尤其是在List末端增删一个元素,二者效率不相上下。
此题考察的是类加载器实例化时进行的操作步骤(加载–>连接->初始化)。
父类静态变量、
父类静态代码块、
子类静态变量、
子类静态代码块、
父类非静态变量(父类实例成员变量)、
父类构造函数、
子类非静态变量(子类实例成员变量)、
子类构造函数。
Hashtable,HashMap,ConcurrentHashMap
线程不安全的HashMap
因为多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
HashMap
HashMap内部实现是一个桶数组,每个桶中存放着一个单链表的头结点。其中每个结点存储的是一个键值对整体(Entry),HashMap采用拉链法解决哈希冲突
效率低下的HashTable容器
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
ConcurrentHashMap的锁分段技术
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
hashcode() 方法,在object类中定义如下:
1 | public native int hashCode(); |
native说明是一个本地方法,它的实现是根据本地机器相关的。当然我们可以在自己写的类中覆盖hashcode()方法,比如String、Integer、Double。。。。等等这些类都是覆盖了hashcode()方法的
例如String类中:就是以31为权,每一位为字符的ASCII值进行运算,用自然溢出来等效取模。(为什么取31?主要是因为31是一个奇质数,所以31i=32i-i=(i<<5)-i,这种位移与减法结合的计算相比一般的运算快很多).
1 | public int hashCode() { |
HashMap 底层是基于 数组 + 链表 组成的
实现 抽象类使用extends关键字来继承抽象类。如果子类不是抽象类的话,它需要提供抽象类中所有声明的方法的实现。子类使用关键字implements来实现接口。它需要提供接口中所有声明的方法的实现。
抽象类和接口的区别
由于Java不支持多继承,子类不能够继承多个类,但可以实现多个接口。因此你就可以使用接口来解决它。
接口可以继承多个接口。
java类是单继承的。classB Extends classA
java接口可以多继承。Interface3 Extends Interface0, Interface1, interface……
不允许类多重继承的主要原因是,如果A同时继承B和C,而B和C同时有一个D方法,A如何决定该继承那一个呢?
但接口不存在这样的问题,接口全都是抽象方法继承谁都无所谓,所以接口可以继承多个接口。
方法递归调用产生这种结果
栈是线程私有的,他的生命周期与线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口灯信息。局部变量表又包含基本数据类型,对象引用类型(局部变量表编译器完成,运行期间不会变化)
所以我们可以理解为栈溢出就是方法执行是创建的栈帧超过了栈的深度。那么最有可能的就是方法递归调用产生这种结果。栈溢出(StackOverflowError)
NIO是为了弥补传统I/O工作模式的不足而研发的,NIO的工具包提出了基于Selector(选择器)、Buffer(缓冲区)、Channel(通道)的新模式;Selector(选择器)、可选择的Channel(通道)和SelectionKey(选择键)配合起来使用,可以实现并发的非阻塞型I/O能力。
NIO的工作原理是什么?
在并发型服务器程序中使用NIO,实际上是通过网络事件驱动模型实现的。我们应用Select机制,不用为每一个客户端连接新启线程处理,而是将其注册到特定的Selector对象上,这就可以在单线程中利用Selector对象管理大量并发的网络连接,更好的利用了系统资源;采用非阻塞I/O的通信方式,不要求阻塞等待I/O操作完成即可返回,从而减少了管理I/O连接导致的系统开销,大幅度提高了系统性能。
当有读或写等注册事件发生时,可以从Selector中获得相应的SelectionKey,从SelectionKey中可以找到发生的事件和该事件所发生的具体的SelectableChannel,以获得客户端发送过来的数据。由于在非阻塞网络I/O中采用了事件触发机制,处理程序可以得到系统的主动通知,从而可以实现底层网络I/O无阻塞、流畅地读写,而不像在原来的阻塞模式下处理程序需要不断循环等待。使用NIO,可以编写出性能更好、更易扩展的并发型服务器程序。
并发型服务器程序的实现代码:应用NIO工具包,基于非阻塞网络I/O设计的并发型服务器程序与以往基于阻塞I/O的实现程序有很大不同,在使用非阻塞网络I/O的情况下,程序读取数据和写入数据的时机不是由程序员控制的,而是Selector决定的。
使用非阻塞型I/O进行并发型服务器程序设计分三个部分:1. 向Selector对象注册感兴趣的事件;2.从Selector中获取所感兴趣的事件;3. 根据不同的事件进行相应的处理。
在进行并发型服务器程序设计时,通过合理地使用NIO工具包,就可以达到一个或者几个Socket线程就可以处理N多个Socket的连接,大大降低我们对服务器程序的预算压力。同时我们利用它更好地提高系统的性能,使我们的工作得到更加有效地开展。
Java中Class.forName和classloader都可以用来对类进行加载。
Class.forName(“className”);
其实这种方法调运的是:Class.forName(className, true, ClassLoader.getCallerClassLoader())方法
参数一:className,需要加载的类的名称。
参数二:true,是否对class进行初始化(需要initialize)
参数三:classLoader,对应的类加载器ClassLoader.laodClass(“className”);
其实这种方法调运的是:ClassLoader.loadClass(name, false)方法
参数一:name,需要加载的类的名称
参数二:false,这个类加载以后是否需要去连接(不需要linking)可见Class.forName除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classloader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
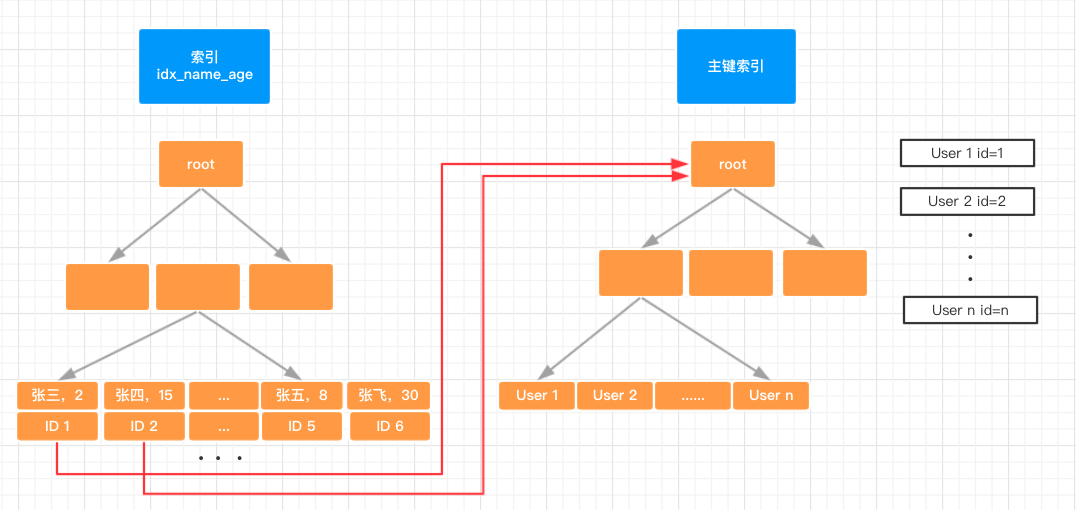
Tomcat 的总体结构
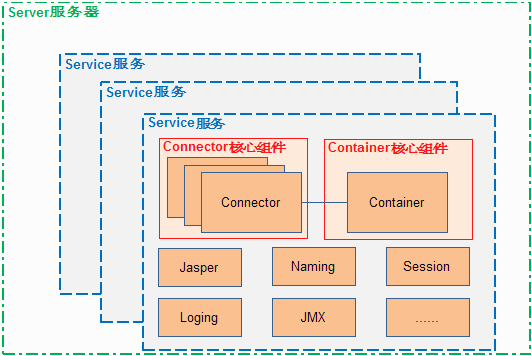
从上图中可以看出 Tomcat 的心脏是两个组件:Connector 和 Container,关于这两个组件将在后面详细介绍。Connector 组件是可以被替换,这样可以提供给服务器设计者更多的选择,因为这个组件是如此重要,不仅跟服务器的设计的本身,而且和不同的应用场景也十分相关,所以一个 Container 可以选择对应多个 Connector。多个 Connector 和一个 Container 就形成了一个 Service,Service 的概念大家都很熟悉了,有了 Service 就可以对外提供服务了,但是 Service 还要一个生存的环境,必须要有人能够给她生命、掌握其生死大权,那就非 Server 莫属了。所以整个 Tomcat 的生命周期由 Server 控制。
什么是类加载器?
虚拟机设计团队把类加载阶段中的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。实现这个动作的代码模块称为“类加载器”。

工具
探索可支持和加速 TensorFlow 工作流程的工具。

Colaboratory 是一个免费的 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行。借助 Colaboratory,您只需点击一下鼠标,即可在浏览器中执行 TensorFlow 代码。
一套可视化工具,用于理解、调试和优化TensorFlow程序。
一种无代码的方式探究机器学习模型的工具,对模型的理解、调试和公平性很有用。可在TensorFlow和Jupyter或CoLab笔记本中使用。
全面的机器学习基准测试套件,用于衡量机器学习软件框架、机器学习硬件加速器和机器学习云端平台的性能。
XLA(加速线性代数)是一种特定领域的线性代数编译器,能够优化TensorFlow计算,它可以提高服务器和移动平台的运行速度改进内存使用情况和可移植性。
在浏览器中设计神经网络。别担心,不会使浏览器崩溃。
加入TensorFlow Research Cloud(TFRC)计划后,研究人员可于申请访问Cloud TPU来加快实现下一波研究突破;我们免费提供1000个Cloud TPU.

今天在工作中,lz要在Linux系统上运行一个java程序,这个程序要在系统中持续运行。随后lz无意将ssh窗口关掉了,发现java程序停止了。原来,当使用ssh连接到系统运行程序的时候,该程序已经和你的ssh连接绑定了。如果你关闭连接,该程序就会停止。还有一个情景:如果要在后台运行多个java程序的时候,就需要启动多个ssh窗口,这样很麻烦。有没有方法来解决这个问题呢?答案是肯定的。
1.使用nohup来执行命令,它会把命令自动调到linux后台运行,不锁定当前ssh窗口,也不会被ctrl + c,alt + F4之类打断程序的动行。
1 | nohup java -jar test.jar & |
执行完该命令后,终端会显示如下信息:
1 | [1] 27945 |
[1]:该后台任务的jobid
27945:是该进程的pid
nohup.out:是该任务的输出位置
2.要指定重定向的文件,如下:
1 | nohup java -jar test.jar > test.log 2>&1 & |
3.如果一个任务已经在前台执行,那就使用以下方法来将任务调整到后台:
(1)首先,在正在执行任务的终端使用ctrl+z
1 | [1]+ 已停止 java -jar test.jar |
(2)使用bg命令将该任务调整至后台(fg与之相反,将后台任务调整至前台)
1 | bg %1(1是jobid) |
如果不知道jobid,也可以使用jobs命令来查询。
但是任务的输出还是会打印到终端上的(具体怎么将输出重定向到别的地方,lz也不造)。而且,这时该任务还是与当前终端相关联的,关闭终端还是会断掉该任务的。使用下面命令来解决:
1 | disown -h %1 |
这样再也不用担心关掉终端会停止掉任务喽!!!
PS:再来说说nohup吧。nohup的意思是no hang up,就是说关掉终端是不会挂掉程序的。如果开始执行命令时只使用&:
1 | java -jar test.jar & |
那么该任务也会在后台执行,但是一旦关掉终端该任务还是会挂掉,所以这就是nohup的用处了。
git 整合来自不同分支的修改主要有两种方法:merge 操作和rebase操作,
merge初学者可能很熟悉。我们今天来主要说一下 rebase 操作,文章结尾会简单说一下 merge 操作的 –no-ff 参数问题。
rebase的简单定义:你可以把某一分支的所有修改都移至另外一个分支就像重新播放一样。
有点儿像金庸武侠小说里面的乾坤大挪移。
举个🌰
假设我们本地库的代码,如下所示
1 | A---B---C remotes/origin/master |
如果此时我们执行 git pull 操作,就会变成下面的样子,因为 pull 默认执行的是 merge 操作,多出来H这次没必要的提交。如下所示
1 | A---B---C remotes/origin/master |
如果我们执行 git pull –rebase 操作,将会变成下面的样子,这里我们用rebase代替了默认的merge操作
1 | remotes/origin |
rebase 作用就是变成线性了,这在多人协作的情况变得非常关键。因为多人合作是不允许随意制造分叉的。大家可以参考我这篇文章。
这就引出了这篇博文要主要阐述的问题,rebase golden rule 问题。
Rebase golden rule
“No one shall rebase a shared branch” — Everyone about rebase
简单来说就是不要在你的公共分支上做任何rebase操作。
再举一个🌰。
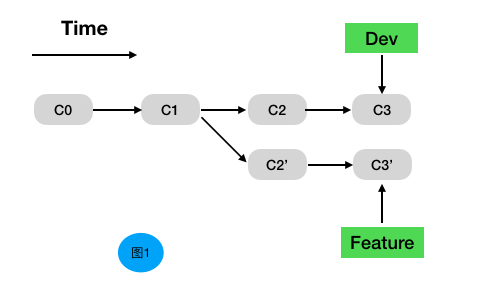
图一是我们做rebase操作前的样子
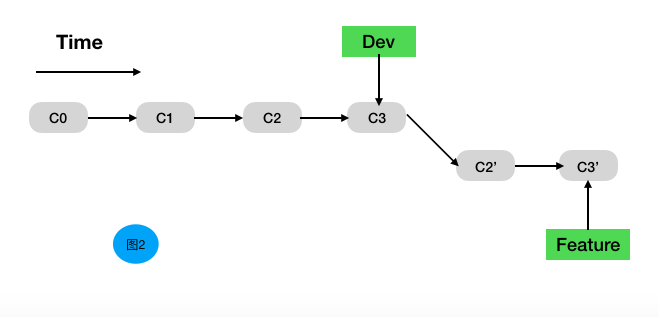
图二是我们正确rebase的结果,即在feature分支执行rebase develop命令
图三是我们错误rebase的结果,即违反黄金法则的结果,我们在develop分支上执行了rebase feature操作
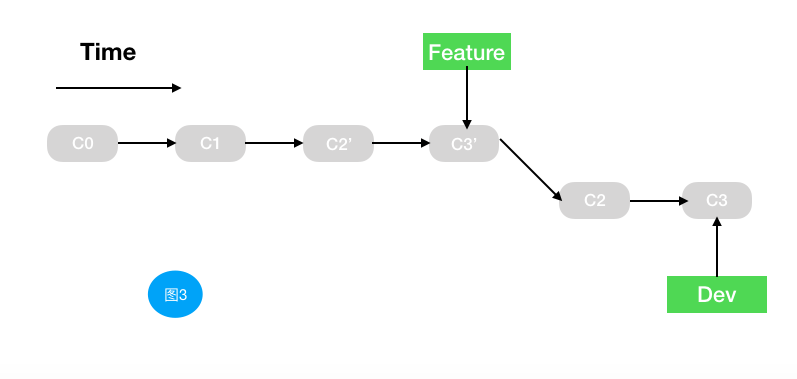
当我们在图三这种情况下对develop分支进行提交的话,会发现和远程分支冲突,然后我们手动或自动解决冲突,继续提交上去之后发现,我们修改的功能代码已经提交上去了,但是当我们看我们提交历史的记录的时候会发现有一部分重复的提交log。
这就是问题所在,你的项目组长是绝对不允许在他的项目里出现这种情况,因为会影响后续的代码追查,code review等问题。
说完了这个问题,这篇博文的主要任务基本完成了,最后在简单说一下 merge 的 –no-ff 参数,这也是我们在分支合并的时候经常遇到的问题。
–no-ff 的意思就是关闭 merge 的 fast-forwarded,merge 操作默认执行的是 fast-forwarded。
fast-forwarded 的意思就是在合并分支的时候,如果不涉及三方合并,git 只会简单的移动指针。
再再举一个🌰
1 | dev |
此时我们执行 merge –no-ff 操作,将会得到如下图
1 | dev |
执行 merge 之后得到的结果如下
1 | dev |
如上git 将指针从C移到了E。
简单来说就是 –no-ff 的作用就是保持分支的非线性。方便我们看到分支的变化。
本文作者: Frank
本文链接: http://hellofrank.github.io/2018/04/27/Git-Rebase-黄金法则问题/
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
dio是一个强大的Dart Http请求库,支持Restful API、FormData、拦截器、请求取消、Cookie管理、文件上传/下载、超时等…
1 | dependencies: |
1 | import 'package:dio/dio.dart'; |
发起一个 GET 请求 :
1 | Response response; |
发起一个 POST 请求:
1 | response = await dio.post("/test", data: {"id": 12, "name": "wendu"}); |
发起多个并发请求:
1 | response = await Future.wait([dio.post("/info"), dio.get("/token")]); |
下载文件:
1 | response = await dio.download("https://www.google.com/", "./xx.html"); |
发送 FormData:
1 | FormData formData = new FormData.from({ |
通过FormData上传多个文件:
1 | FormData formData = new FormData.from({ |
监听发送(上传)数据进度:
1 | response = await dio.post( |
…你可以在这里获取所有示例代码.
你可以使用默认配置或传递一个可选 Options参数来创建一个Dio实例 :
1 | Dio dio = new Dio; // 使用默认配置 |
Dio实例的核心API是 :
Future
1 | response = await request( |
为了方便使用,Dio提供了一些其它的Restful API, 这些API都是request的别名。
Future
Future
Future
Future
Future
Future
Future
Future
{OnDownloadProgress onProgress, data, bool flush: false, Options options,CancelToken cancelToken})
下面是所有的请求配置选项。 如果请求method没有指定,则默认为GET :
1 | { |
这里有一个完成的示例.
当请求成功时会返回一个Response对象,它包含如下字段:
1 | { |
示例如下:
1 | Response response = await dio.get("https://www.google.com"); |
每一个 Dio 实例都有一个请求拦截器 RequestInterceptor 和一个响应拦截器 ResponseInterceptor, 通过拦截器你可以在请求之前或响应之后(但还没有被 then 或 catchError处理)做一些统一的预处理操作。
1 | dio.interceptor.request.onSend = (Options options){ |
如果你想移除拦截器,你可以将它们置为null:
1 | dio.interceptor.request.onSend = null; |
在所有拦截器中,你都可以改变请求执行流, 如果你想完成请求/响应并返回自定义数据,你可以返回一个 Response 对象或返回 dio.resolve(data)的结果。 如果你想终止(触发一个错误,上层catchError会被调用)一个请求/响应,那么可以返回一个DioError 对象或返回 dio.reject(errMsg) 的结果.
1 | dio.interceptor.request.onSend = (Options options) { |
拦截器中不仅支持同步任务,而且也支持异步任务, 下面是在请求拦截器中发起异步任务的一个实例:
1 | dio.interceptor.request.onSend = (Options options) async { |
你可以通过调用拦截器的 lock()/unlock 方法来锁定/解锁拦截器。一旦请求/响应拦截器被锁定,接下来的请求/响应将会在进入请求/响应拦截器之前排队等待,直到解锁后,这些入队的请求才会继续执行(进入拦截器)。这在一些需要串行化请求/响应的场景中非常实用,后面我们将给出一个示例。
1 | tokenDio = new Dio(); //Create a new instance to request the token. |
Clear()
你也可以调用拦截器的clear()方法来清空等待队列。
当请求拦截器被锁定时,接下来的请求将会暂停,这等价于锁住了dio实例,因此,Dio示例上提供了请求拦截器lock/unlock的别名方法:
dio.lock() == dio.interceptor.request.lock()
dio.unlock() == dio.interceptor.request.unlock()
dio.clear() == dio.interceptor.request.clear()
假设这么一个场景:出于安全原因,我们需要给所有的请求头中添加一个csrfToken,如果csrfToken不存在,我们先去请求csrfToken,获取到csrfToken后,再发起后续请求。 由于请求csrfToken的过程是异步的,我们需要在请求过程中锁定后续请求(因为它们需要csrfToken), 直到csrfToken请求成功后,再解锁,代码如下:
1 | dio.interceptor.request.onSend = (Options options) { |
完整的示例代码请点击 这里.
当请求过程中发生错误时, Dio 会包装 Error/Exception 为一个 DioError:
1 | try { |
1 | { |
1 | enum DioErrorType { |
默认情况下, Dio 会将请求数据(除过String类型)序列化为 JSON. 如果想要以 application/x-www-form-urlencoded格式编码, 你可以显式设置contentType :
1 | //Instance level |
这里有一个示例.
Dio支持发送 FormData, 请求数据将会以 multipart/form-data方式编码, FormData中可以一个或多个包含文件 .
1 | FormData formData = new FormData.from({ |
注意: 只有 post 方法支持发送 FormData.
这里有一个完整的示例.
转换器Transformer 用于对请求数据和响应数据进行编解码处理。Dio实现了一个默认转换器DefaultTransformer作为默认的 Transformer. 如果你想对请求/响应数据进行自定义编解码处理,可以提供自定义转换器,通过 dio.transformer设置。
请求转换器
Transformer.transformRequest(...)只会被用于 ‘PUT’、 ‘POST’、 ‘PATCH’方法,因为只有这些方法才可以携带请求体(request body)。但是响应转换器Transformer.transformResponse()会被用于所有请求方法的返回数据。
虽然在拦截器中也可以对数据进行预处理,但是转换器主要职责是对请求/响应数据进行编解码,之所以将转化器单独分离,一是为了和拦截器解耦,二是为了不修改原始请求数据(如果你在拦截器中修改请求数据(options.data),会覆盖原始请求数据,而在某些时候您可能需要原始请求数据). Dio的请求流是:
请求拦截器 >> 请求转换器 >> 发起请求 >> 响应转换器 >> 响应拦截器 >> 最终结果。
这是一个自定义转换器的示例.
Dio 是使用 HttpClient发起的http请求,所以你可以通过配置 httpClient来支持代理,示例如下:
1 | dio.onHttpClientCreate = (HttpClient client) { |
完整的示例请查看这里.
有两种方法可以校验https证书,假设我们的后台服务使用的是自签名证书,证书格式是PEM格式,我们将证书的内容保存在本地字符串中,那么我们的校验逻辑如下:
1 | String PEM="XXXXX"; //证书内容 |
X509Certificate是证书的标准格式,包含了证书除私钥外所有信息,读者可以自行查阅文档。另外,上面的示例没有校验host,是因为只要服务器返回的证书内容和本地的保存一致就已经能证明是我们的服务器了(而不是中间人),host验证通常是为了防止证书和域名不匹配。
对于自签名的证书,我们也可以将其添加到本地证书信任链中,这样证书验证时就会自动通过,而不会再走到badCertificateCallback回调中:
1 | dio.onHttpClientCreate = (HttpClient client) { |
注意,通过setTrustedCertificates()设置的证书格式必须为PEM或PKCS12,如果证书格式为PKCS12,则需将证书密码传入,这样则会在代码中暴露证书密码,所以客户端证书校验不建议使用PKCS12格式的证书。
你可以通过 cancel token 来取消发起的请求:
1 | CancelToken token = new CancelToken(); |
注意: 同一个cancel token 可以用于多个请求,当一个cancel token取消时,所有使用该cancel token的请求都会被取消。
完整的示例请参考取消示例.
你可以通过 cookieJar 来自动管理请求/响应cookie.
dio cookie 管理 API 是基于开源库 cookie_jar.
你可以创建一个CookieJar 或 PersistCookieJar 来帮您自动管理cookie, dio 默认使用 CookieJar , 它会将cookie保存在内存中。 如果您想对cookie进行持久化, 请使用 PersistCookieJar , 示例代码如下:
1 | var dio = new Dio(); |
PersistCookieJar 实现了RFC中标准的cookie策略. PersistCookieJar 会将cookie保存在文件中,所以 cookies 会一直存在除非显式调用 delete 删除.
更多关于 cookie_jar 请参考 : https://github.com/flutterchina/cookie_jar .
此开源项目为Flutter中文网(https://flutterchina.club) 授权 ,license 是 MIT. 如果您喜欢,欢迎star.
Flutter中文网开源项目计划
开发一系列Flutter SDK之外常用(实用)的Package、插件,丰富Flutter第三方库,为Flutter生态贡献来自中国开发者的力量。所有项目将发布在 Github Flutter中文网 Organization ,所有源码贡献者将加入到我们的Organization,成为成员. 目前社区已有几个开源项目开始公测,欢迎您加入开发或测试,详情请查看: Flutter中文网开源项目。 如果您想加入到“开源项目计划”, 请发邮件到824783146@qq.com, 并附上自我介绍(个人基本信息+擅长/关注技术)。
Please file feature requests and bugs at the issue tracker.
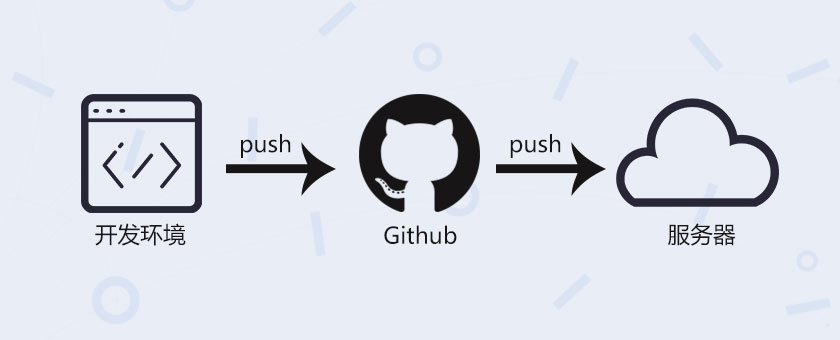
相信很多码农都玩过了Git,如果对Git只是一知半解,可以移步LV写的 GIT常用操作总结,下面介绍到的一些关于 Git 的概念就不再赘述。
为啥想写这篇文章?主要是因为部门服务器因为安全性原因不允许SCP上传文件进行应用部署,然后有一些应用是放在Github上的,然后部署应用的步骤就变成:
1.git clone github项目 本地目录
2.配置一下应用的pm2.json并reload
3.Nginx配置一下反向代理并restart
当然如果只是一次性部署上去就不再修改的话并没啥问题,但是要是项目持续性修改迭代的话,就比较麻烦了,我们就在不断的重复着上面的步骤。作为一个码农,怎么允许不断的重复同样的工作,于是Github webhooks闪亮登场。
刚好符合了这几个条件,那接下来就看看如何进行网站自动化部署,主要会从下面几点来讲解:
auto_build.sh
1 | #! /bin/bash |
Note: 在执行上面shell脚本之前我们必须第一次手动git clone项目进去
Github webhooks需要跟我们的服务器进行通信,确保是可以推送到我们的服务器,所以会发送一个带有X-Hub-Signature的POST请求,为了方便我们直接用第三方的库github-webhook-handler来接收参数并且做监听事件的处理等工作。
1 | npm i github-webhook-handler -S |
index.js
1 | var http = require('http'); |
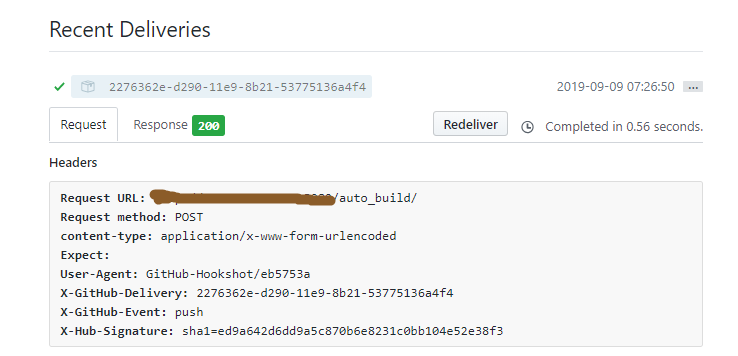
上面就是利用Github webhooks进行网站自动化部署的全部内容了,不难发现其实这项技术还是有局限性的,那就是依赖于github,一般我们选择的都是免费github账号,所有项目都对外,一些敏感项目是不适合放置上去的。
This command could delete list half your files randomly.
don’t use it at home and other places. this is a real gun, use it wisely…
feel free to post your story on 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 灭霸脚本
这个命令会随机“删掉”您一半的文件。。
请不要在家里或其他地方使用。这是真家伙,要小心…
你可以在```Story.md```文件里发布你的故事,期待中…
## 特别说明
> 1. 支持mac系统,但是需要使用到```gshuf```命令,需要通过```brew```安装,安装命令如下:
```shell
#安装brew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
#安装gshuf
brew install coreutils
`
- 此脚本只会列出当前目录一半的文件。并且。。。总之小心点。。。
Invokes Thanos to remove each object with probability 1/2. It works with files, registry, environment variables, functions, variables, aliases and certificates.
For help, use Get-Help .\Invoke-Thanos.ps1. Be sure to not actually invoke it!
1 | #!/bin/sh |
本人在线上服务器上运行了一次,…
本文分享了唯品会数据库Docker的异地容灾项目实践经验,项目中针对用户数据库的异地恢复场景的需求进行开发和测试,整合了网络,存储、调度、监控,镜像等多个模块。在实施完成后,从技术上总结关于选型、开发、踩坑、测试等方面的经验。
数据库Docker的异地备份恢复容灾项目,针对用户数据库的异地备份恢复场景的需求进行开发和测试,整合了容器网络、存储、调度、监控、镜像等多个模块。同时针对数据库的日常运维工作开发了监控、资源调度、日志、Puppet自动推送等工具。
通过Docker天生隔离性和快速部署等特点,实现在单台物理机上运行多个数据库备份/恢复实例,大大提高服务器使用率,节省大量成本。通过对Docker本身和相关组件的研究和改造,从普通开源产品落地到公司内部生产环境,积累宝贵的开发经验。通过对Docker已经在其上层运行的数据库日常运维和监控,也积累宝贵的Docker运维经验,为更大规模推广容器提供基础。
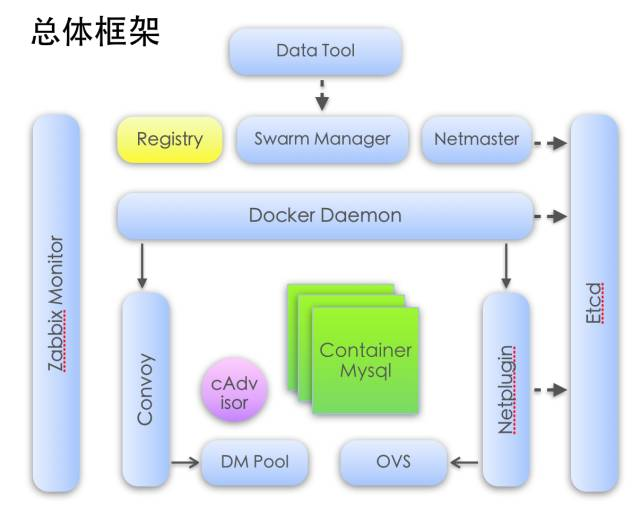
通过实践,证明容器技术在易用性,可管理性,快速部署具备天然的优势。在资源利用率方面,容器部署在上百个物理节点上,提供约500多个数据库灾备实例,提升了硬件资源的利用率,节约了约400台物理机的采购成本。这些是容器技术带来的实实在在收益。在资源分配与隔离方面,又不输于虚拟机。CPU、内存、磁盘IO、网络IO限流等技术的应用,保证了资源的合理使用,从机制上阻止了单一实例的资源过分消耗的问题。
稳定性是使用容器技术非常关注的一个点,也是基石。MySQL备份/恢复属于CPU密集 + 磁盘IO密集 + 网络IO密集型业务,对于Docker daemon是个较大的考验。就目前来看,限制每台宿主机的容器数量(5个左右)的情况下,集群跑了三个多月没有出现因为容器负载过大导致的crash现象,还是值得信赖的。遇到的唯一相关问题是Docker daemon挂死,具体现象是docker info、docker ps没有响应,docker volume、docker images 正常,下面的容器运行正常。这是偶发事件,无法重现,以后需要继续观察。
由于容器以进程方式存在,体现出几乎与物理机上相当的性能,Overheads极低(低于10%)。从数据抽取任务的结果来看,与物理机相比,使用容器对成功率没有影响,效率也差不多。这也很符合最初预想,不管跑容器还是外部服务从物理机角度来说它们之间是没有什么区别的,都是一个进程,唯一不同是父进程不一样而已。
以上是容器“RUN”带来的好处,通过统一开发流程,应用微服务化,CI/CD等方面的改进,能够进一步利用容器“BUILD”、“SHIP” 优势,容器技术还来的潜力是巨大的。要说容器技术的缺点,还真的不明显。硬要提的话一个是需要一定的学习成本,改变开发流程与方式,一个是开发人员对容器技术的接受程度。这个项目仅用了不到二百人/天,对于一个采用新技术的项目来说,真的是很低的了。一开始我们也担心因为采用新技术导致开发推广有困难,后来实际能通过技术上解决问题,打消了大部分用户对使用Docker的疑虑,反而有助于该技术的普遍应用。
关于Docker daemon版本的选择,我们之前是有过一些讨论的。现在Docker社区非常活跃,当时我们用1.10.3, 到现在已经出了两个新版本了。在功能满足的前提下,稳定性是第一考量。Docker自1.9.0引入CNM网络模型,1.10算是比较成熟。CNM是我们希望在这个项目尝试的一部分。网络与Volume插件功能与稳定性的提升,开始支持磁盘IO读写限速,Device Mapper的支持,等等,都是选择了这个版本的原因。另外,Docker插件的引入,很好地解耦了Docker与底层模块的关系,使我们可以专注于底层(网络、存储)实现而不需要修改Docker daemon本身,同时避免产生升级依赖。
容器外部卷使用Convoy,以插件的形式支持容器持久化数据。容器本身与外部卷均使用Device Mapper作为底层。没有选择分布式存储原因,主要是为了简化实现,更稳定。通过限制每个容器的BlkioDeviceReadBps、BlkioDeviceWriteBps、BlkioDeviceReadIOps、BlkioDeviceWriteIOps,使磁盘IO稳定地达到相当于95%物理机性能。
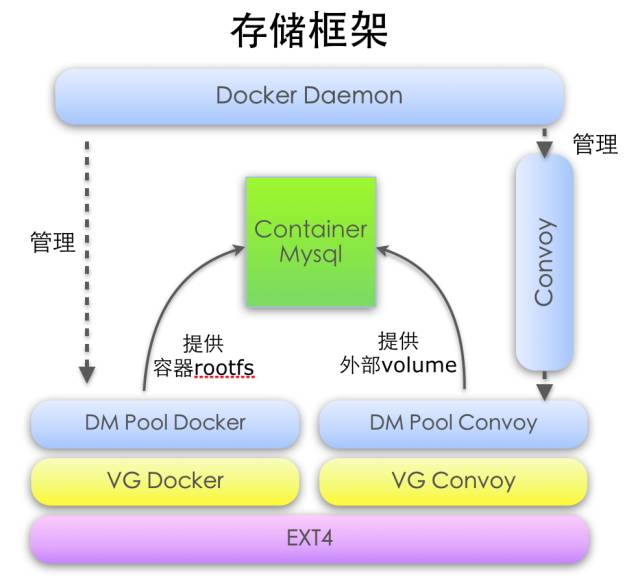
对于Device Mapper,因为是红帽推荐的,而OS又是用的CentOS7.2, 所以就用了它。测试过程中发现Device Mapper健壮性不是很好,仅仅在低并发下,也会出现容器删除失败的情况,容器并发启停偶尔出现找不到设备的情况。这种使用映射关系的设备,功能是丰富,实现上过于复杂,每次对设备的修改都需要额外去更新Metadata,并发场景出错的机会就大了。让我再选的话我会考虑Overlay这种更简单的driver。
对于Convoy,是来自Rancher的产品,Go语言,仍然处于未成熟阶段,版本号0.5, 并没有完全实现Volume Plugin接口。相比其它模块它的问题也是最多的,例如Volume创建失败,无法删除,UNIX Socket泄漏,重名冲突,异常自动退出等。属于能用,但未完善的状态,你自己得有一定开发调试能力去解决发现的问题。其它几个存储插件情况也差不多,Flocker、Blockbridge、Horcrux等等,有的连第一个正式发布版都还没有,Convoy反而相对好点,有点烂柿子堆里挑的感觉。
容器监控在这个项目里还可以有很大的空间可以改进。项目里用的是cAdvisor,容器内top、free、iostat命令劫持,基于已有的Zabbix体系作数据收集与展示。结论是Zabbix完全不合适做容器监控,数据收集密度,展示质量,灵活度都没能满足需求。
后来在测试中尝试使用Telegraf + InfluxDB + Grafana。 只需要Grafana简单的配置,能够帮忙我们清晰地展示容器及服务进程CPU、内存、网络、磁盘等情况。Grafana上SQL查询语句的调试与开发,确实需要不少的时间,但这个工作量是一次性的。因为是Go写的,Telegraf CPU占用属于比较低的水平(0.4 – 5%)。功能上比较丰富,同时支持外部进程与容器的数据收集,多达55种数据源插件,有它就不需要布cAdvisor了,个人比较推荐。需要告警的同学,可以考虑把influxDB改成Prometheus。它包含Alertmanager实现Email、PagerDuty等消息通知。数据Backend可以选择自带的DB,也可以外接influxDB、Graphite、OpenTSDB等流行方案。
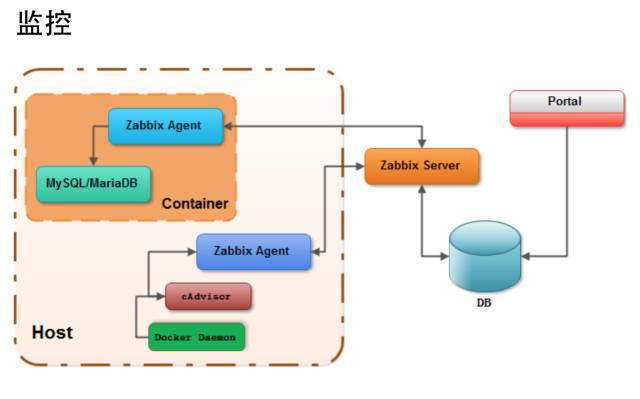
监控领域业界已经有很多开源方案可以参考,以下是要衡量的标准:易扩展、开销低、入侵小、大集中、易部署、实时性、展现清晰灵活。这方面希望与各位有更多的交流。
基于 vue (基本上是它听起来的样子) 来构造 electron 应用程序的样板代码。
什么是electron?
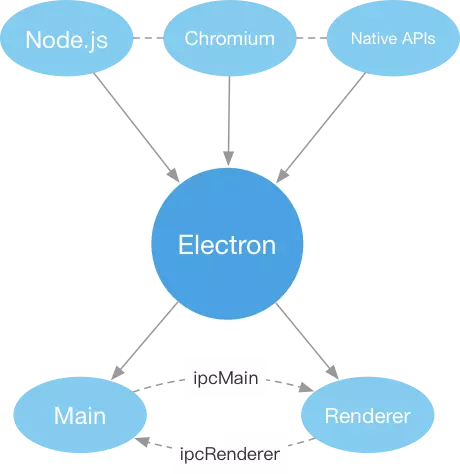
electron由Node.js+Chromium+Native APIs构成。你可以理解成,它是一个得到了Node.js和基于不同平台的Native APIs加强的Chromium浏览器,可以用来开发跨平台的桌面级应用。
它的开发主要涉及到两个进程的协作——Main(主)进程和Renderer(渲染)进程。简单的理解两个进程的作用:
ipcMain和ipcRenderer来进行通信。通过事件监听和事件派发来实现两个进程通信,从而实现Main或者Renderer进程里不能实现的某些功能。该样板代码被构建为 vue-cli 的一个模板,并且包含多个选项,可以自定义你最终的脚手架程序。本项目需要使用 node@^7 或更高版本。electron-vue 官方推荐 yarn 作为软件包管理器,因为它可以更好地处理依赖关系,并可以使用 yarn clean 帮助减少最后构建文件的大小。
1 | # 安装 vue-cli 和 脚手架样板代码 |
1 | my-project |
1 | app.asar |

一种写JavaScript更合理的代码风格。
Note: 本指南假设你使用了 Babel, 并且要求你使用 babel-preset-airbnb 或者其他同等资源。 并且假设你在你的应用中安装了 shims/polyfills ,使用airbnb-browser-shims 或者相同功能。



其他代码风格指南
1.1 原始值: 当你访问一个原始类型的时候,你可以直接使用它的值。
stringnumberbooleannullundefinedsymbol1 | const foo = 1; |
1.2 复杂类型: 当你访问一个复杂类型的时候,你需要一个值得引用。
objectarrayfunction1 | const foo = [1, 2]; |
2.1 使用 const 定义你的所有引用;避免使用 var。 eslint: prefer-const, no-const-assign
为什么? 这样能够确保你不能从新分配你的引用,否则可能导致错误或者产生难以理解的代码。.
1 | // bad |
2.2 如果你必须重新分配你的引用, 使用 let 代替 var。 eslint: no-var
为什么?
let是块级作用域,而不像var是函数作用域.
1 | // bad |
2.3 注意,let 和 const 都是块级范围的。
1 | // const 和 let 只存在于他们定义的块中。 |
3.1 使用字面语法来创建对象。 eslint: no-new-object
1 | // bad |
3.2 在创建具有动态属性名称的对象时使用计算属性名。
为什么? 它允许你在一个地方定义对象的所有属性。
1 | |
3.3 使用对象方法的缩写。 eslint: object-shorthand
1 | // bad |
3.4 使用属性值的缩写。 eslint: object-shorthand
为什么? 它的写法和描述较短。
1 | const lukeSkywalker = 'Luke Skywalker'; |
3.5 在对象声明的时候将简写的属性进行分组。
为什么? 这样更容易的判断哪些属性使用的简写。
1 | const anakinSkywalker = 'Anakin Skywalker'; |
3.6 只使用引号标注无效标识符的属性。 eslint: quote-props
为什么? 总的来说,我们认为这样更容易阅读。 它提升了语法高亮显示,并且更容易通过许多 JS 引擎优化。
1 | // bad |
3.7 不能直接调用 Object.prototype 的方法,如: hasOwnProperty 、 propertyIsEnumerable 和 isPrototypeOf。
为什么? 这些方法可能被一下问题对象的属性追踪 - 相应的有
{ hasOwnProperty: false }- 或者,对象是一个空对象 (Object.create(null))。
1 | // bad |
3.8 更喜欢对象扩展操作符,而不是用 Object.assign 浅拷贝一个对象。 使用对象的 rest 操作符来获得一个具有某些属性的新对象。
1 | // very bad |
4.1 使用字面语法创建数组。 eslint: no-array-constructor
1 | // bad |
4.2 使用 Array#push 取代直接赋值来给数组添加项。
1 | const someStack = []; |
4.3 使用数组展开方法 ... 来拷贝数组。
1 | // bad |
4.4 将一个类数组对象转换成一个数组, 使用展开方法 ... 代替 Array.from。
1 | const foo = document.querySelectorAll('.foo'); |
4.5 对于对迭代器的映射,使用 Array.from 替代展开方法 ... , 因为它避免了创建中间数组。
1 | // bad |
4.6 在数组回调方法中使用 return 语句。 如果函数体由一个返回无副作用的表达式的单个语句组成,那么可以省略返回值, 具体查看 8.2。 eslint: array-callback-return
1 | // good |
4.7 如果数组有多行,则在开始的时候换行,然后在结束的时候换行。
1 | // bad |
5.1 在访问和使用对象的多个属性的时候使用对象的解构。 eslint: prefer-destructuring
为什么? 解构可以避免为这些属性创建临时引用。
1 | // bad |
5.2 使用数组解构。 eslint: prefer-destructuring
1 | const arr = [1, 2, 3, 4]; |
5.3 对于多个返回值使用对象解构,而不是数组解构。
为什么? 你可以随时添加新的属性或者改变属性的顺序,而不用修改调用方。
1 | // bad |
6.1 使用单引号 '' 定义字符串。 eslint: quotes
1 | // bad |
6.2 使行超过100个字符的字符串不应使用字符串连接跨多行写入。
为什么? 断开的字符串更加难以工作,并且使代码搜索更加困难。
1 | // bad |
6.3 当以编程模式构建字符串时,使用字符串模板代替字符串拼接。 eslint: prefer-template template-curly-spacing
为什么? 字符串模板为您提供了一种可读的、简洁的语法,具有正确的换行和字符串插值特性。
1 | // bad |
6.5 不要转义字符串中不必要的字符。 eslint: no-useless-escape
为什么? 反斜杠损害了可读性,因此只有在必要的时候才会出现。
1 | // bad |
7.1 使用命名的函数表达式代替函数声明。 eslint: func-style
为什么? 函数声明是挂起的,这意味着在它在文件中定义之前,很容易引用函数。这会损害可读性和可维护性。如果您发现函数的定义是大的或复杂的,以至于它干扰了对文件的其余部分的理解,那么也许是时候将它提取到它自己的模块中了!不要忘记显式地命名这个表达式,不管它的名称是否从包含变量(在现代浏览器中经常是这样,或者在使用诸如Babel之类的编译器时)。这消除了对错误的调用堆栈的任何假设。 (Discussion)
1 | // bad |
7.2 Wrap立即调用函数表达式。 eslint: wrap-iife
为什么? 立即调用的函数表达式是单个单元 - 包装, 并且拥有括号调用, 在括号内, 清晰的表达式。 请注意,在一个到处都是模块的世界中,您几乎不需要一个 IIFE 。
1 | // immediately-invoked function expression (IIFE) 立即调用的函数表达式 |
7.3 切记不要在非功能块中声明函数 (if, while, 等)。 将函数赋值给变量。 浏览器允许你这样做,但是他们都有不同的解释,这是个坏消息。 eslint: no-loop-func
7.4 注意: ECMA-262 将 block 定义为语句列表。 函数声明不是语句。
1 | // bad |
7.5 永远不要定义一个参数为 arguments。 这将会优先于每个函数给定范围的 arguments 对象。
1 | // bad |
7.6 不要使用 arguments, 选择使用 rest 语法 ... 代替。 eslint: prefer-rest-params
为什么?
...明确了你想要拉取什么参数。 更甚, rest 参数是一个真正的数组,而不仅仅是类数组的arguments。
1 | // bad |
7.7 使用默认的参数语法,而不是改变函数参数。
1 | // really bad |
7.8 避免使用默认参数的副作用。
为什么? 他们很容易混淆。
1 | var b = 1; |
7.9 总是把默认参数放在最后。
1 | // bad |
7.10 永远不要使用函数构造器来创建一个新函数。 eslint: no-new-func
为什么? 以这种方式创建一个函数将对一个类似于
eval()的字符串进行计算,这将打开漏洞。
1 | // bad |
7.11 函数签名中的间距。 eslint: space-before-function-paren space-before-blocks
为什么? 一致性很好,在删除或添加名称时不需要添加或删除空格。
1 | // bad |
7.12 没用变异参数。 eslint: no-param-reassign
为什么? 将传入的对象作为参数进行操作可能会在原始调用程序中造成不必要的变量副作用。
1 | // bad |
7.13 不要再分配参数。 eslint: no-param-reassign
为什么? 重新分配参数会导致意外的行为,尤其是在访问
arguments对象的时候。 它还可能导致性能优化问题,尤其是在 V8 中。
1 | // bad |
7.14 优先使用扩展运算符 ... 来调用可变参数函数。 eslint: prefer-spread
为什么? 它更加干净,你不需要提供上下文,并且你不能轻易的使用
apply来new。
1 | // bad |
7.15 具有多行签名或者调用的函数应该像本指南中的其他多行列表一样缩进:在一行上只有一个条目,并且每个条目最后加上逗号。 eslint: function-paren-newline
1 | // bad |
8.1 当你必须使用匿名函数时 (当传递内联函数时), 使用箭头函数。 eslint: prefer-arrow-callback, arrow-spacing
为什么? 它创建了一个在
this上下文中执行的函数版本,它通常是你想要的,并且是一个更简洁的语法。
为什么不? 如果你有一个相当复杂的函数,你可以把这个逻辑转移到它自己的命名函数表达式中。
1 | // bad |
8.2 如果函数体包含一个单独的语句,返回一个没有副作用的 expression , 省略括号并使用隐式返回。否则,保留括号并使用 return 语句。 eslint: arrow-parens, arrow-body-style
为什么? 语法糖。 多个函数被链接在一起时,提高可读性。
1 | // bad |
8.3 如果表达式跨越多个行,用括号将其括起来,以获得更好的可读性。
为什么? 它清楚地显示了函数的起点和终点。
1 | // bad |
8.4 如果你的函数接收一个参数,则可以不用括号,省略括号。 否则,为了保证清晰和一致性,需要在参数周围加上括号。 注意:总是使用括号是可以接受的,在这种情况下,我们使用 “always” option 来配置 eslint. eslint: arrow-parens
为什么? 减少视觉上的混乱。
1 | // bad |
8.5 避免箭头函数符号 (=>) 和比较运算符 (<=, >=) 的混淆。 eslint: no-confusing-arrow
1 | // bad |
8.6 注意带有隐式返回的箭头函数函数体的位置。 eslint: implicit-arrow-linebreak
1 | // bad |
9.1 尽量使用 class. 避免直接操作 prototype .
为什么?
class语法更简洁,更容易推理。
1 | // bad |
9.2 使用 extends 来扩展继承。
为什么? 它是一个内置的方法,可以在不破坏
instanceof的情况下继承原型功能。
1 | // bad |
9.3 方法返回了 this 来供其内部方法调用。
1 | // bad |
9.4 只要在确保能正常工作并且不产生任何副作用的情况下,编写一个自定义的 toString() 方法也是可以的。
1 | class Jedi { |
9.5 如果没有指定类,则类具有默认的构造器。 一个空的构造器或是一个代表父类的函数是没有必要的。 eslint: no-useless-constructor
1 | // bad |
9.6 避免定义重复的类成员。 eslint: no-dupe-class-members
为什么? 重复的类成员声明将会默认倾向于最后一个 - 具有重复的类成员可以说是一个错误。
1 | // bad |
10.1 你可能经常使用模块 (import/export) 在一些非标准模块的系统上。 你也可以在你喜欢的模块系统上相互转换。
为什么? 模块是未来的趋势,让我们拥抱未来。
1 | // bad |
10.2 不要使用通配符导入。
为什么? 这确定你有一个单独的默认导出。
1 | // bad |
10.3 不要直接从导入导出。
为什么? 虽然写在一行很简洁,但是有一个明确的导入和一个明确的导出能够保证一致性。
1 | // bad |
10.4 只从一个路径导入所有需要的东西。
eslint: no-duplicate-imports
为什么? 从同一个路径导入多个行,使代码更难以维护。
1 | // bad |
10.5 不要导出可变的引用。
eslint: import/no-mutable-exports
为什么? 在一般情况下,应该避免发生突变,但是在导出可变引用时及其容易发生突变。虽然在某些特殊情况下,可能需要这样,但是一般情况下只需要导出常量引用。
1 | // bad |
10.6 在单个导出的模块中,选择默认模块而不是指定的导出。
eslint: import/prefer-default-export
为什么? 为了鼓励更多的文件只导出一件东西,这样可读性和可维护性更好。
1 | // bad |
10.7 将所有的 imports 语句放在所有非导入语句的上边。
eslint: import/first
为什么? 由于所有的
imports 都被提前,保持他们在顶部是为了防止意外发生。
1 | // bad |
10.8 多行导入应该像多行数组和对象一样缩进。
为什么? 花括号和其他规范一样,遵循相同的缩进规则,后边的都好一样。
1 | // bad |
10.9 在模块导入语句中禁止使用 Webpack 加载器语法。
eslint: import/no-webpack-loader-syntax
为什么? 因为在导入语句中使用 webpack 语法,将代码和模块绑定在一起。应该在
webpack.config.js中使用加载器语法。
1 | // bad |
11.1 不要使用迭代器。 你应该使用 JavaScript 的高阶函数代替 for-in 或者 for-of。 eslint: no-iterator no-restricted-syntax
为什么? 这是我们强制的规则。 拥有返回值得纯函数比这个更容易解释。
使用
map()/every()/filter()/find()/findIndex()/reduce()/some()/ … 遍历数组, 和使用Object.keys()/Object.values()/Object.entries()迭代你的对象生成数组。
1 | const numbers = [1, 2, 3, 4, 5]; |
11.2 不要使用发生器。
为什么? They don’t transpile well to ES5.
11.3 如果你必须使用发生器或者无视 我们的建议,请确保他们的函数签名是正常的间隔。 eslint: generator-star-spacing
为什么?
function和*是同一个概念关键字的一部分 -*不是function的修饰符,function*是一个不同于function的构造器。
1 | // bad |
12.1 访问属性时使用点符号。 eslint: dot-notation
1 | const luke = { |
12.2 使用变量访问属性时,使用 []表示法。
1 | const luke = { |
12.3 计算指数时,可以使用 ** 运算符。 eslint: no-restricted-properties.
1 | // bad |
13.1 使用 const 或者 let 来定义变量。 不这样做将创建一个全局变量。 我们希望避免污染全局命名空间。 Captain Planet 警告过我们。 eslint: no-undef prefer-const
1 | // bad |
13.2 使用 const 或者 let 声明每一个变量。 eslint: one-var
为什么? 这样更容易添加新的变量声明,而且你不必担心是使用
;还是使用,或引入标点符号的差别。 你可以通过 debugger 逐步查看每个声明,而不是立即跳过所有声明。
1 | // bad |
13.3 把 const 声明的放在一起,把 let 声明的放在一起。.
为什么? 这在后边如果需要根据前边的赋值变量指定一个变量时很有用。
1 | // bad |
13.4 在你需要的使用定义变量,但是要把它们放在一个合理的地方。
为什么?
let和const是块级作用域而不是函数作用域。
1 | // bad - 不必要的函数调用 |
13.5 不要链式变量赋值。 eslint: no-multi-assign
为什么? 链式变量赋值会创建隐式全局变量。
1 | // bad |
13.6 避免使用不必要的递增和递减 (++, --)。 eslint no-plusplus
为什么? 在eslint文档中,一元递增和递减语句以自动分号插入为主题,并且在应用程序中可能会导致默认值的递增或递减。它还可以用像
num += 1这样的语句来改变您的值,而不是使用num++或num ++。不允许不必要的增量和减量语句也会使您无法预先递增/预递减值,这也会导致程序中的意外行为。
1 | // bad |
13.7 避免在赋值语句 = 前后换行。如果你的代码违反了 max-len, 使用括号包裹。 eslint operator-linebreak.
为什么? 在
=前后换行,可能混淆分配的值。
1 | // bad |
14.1 var 定义的变量会被提升到函数范围的最顶部,但是它的赋值不会。const 和 let 声明的变量受到一个称之为 Temporal Dead Zones (TDZ) 的新概念保护。 知道为什么 typeof 不在安全 是很重要的。
1 | // 我们知道这个行不通 (假设没有未定义的全局变量) |
14.2 匿名函数表达式提升变量名,而不是函数赋值。
1 | function example() { |
14.3 命名函数表达式提升的是变量名,而不是函数名或者函数体。
1 | function example() { |
14.4 函数声明提升其名称和函数体。
1 | function example() { |
更多信息请参考 Ben Cherry 的 JavaScript Scoping & Hoisting。
15.2 条件语句,例如 if 语句使用 ToBoolean 的抽象方法来计算表达式的结果,并始终遵循以下简单的规则:
'' 值为 false 否则为 true1 | if ([0] && []) { |
15.3 对于布尔值使用简写,但是对于字符串和数字进行显式比较。
1 | // bad |
15.4 获取更多信息请查看 Angus Croll 的 Truth Equality and JavaScript 。
15.5 在 case 和 default 的子句中,如果存在声明 (例如. let, const, function, 和 class),使用大括号来创建块 。 eslint: no-case-declarations
为什么? 语法声明在整个
switch块中都是可见的,但是只有在赋值的时候才会被初始化,这种情况只有在case条件达到才会发生。 当多个case语句定义相同的东西是,这会导致问题问题。
1 | // bad |
15.6 三目表达式不应该嵌套,通常是单行表达式。 eslint: no-nested-ternary
1 | // bad |
15.7 避免不必要的三目表达式。 eslint: no-unneeded-ternary
1 | // bad |
15.8 使用该混合运算符时,使用括号括起来。 唯一例外的是标准算数运算符 (+, -, *, & /) 因为他们的优先级被广泛理解。 eslint: no-mixed-operators
为什么? 这能提高可读性并且表明开发人员的意图。
1 | // bad |
16.1 当有多行代码块的时候,使用大括号包裹。 eslint: nonblock-statement-body-position
1 | // bad |
16.2 如果你使用的是 if 和 else 的多行代码块,则将 else 语句放在 if 块闭括号同一行的位置。 eslint: brace-style
1 | // bad |
16.3 如果一个 if 块总是执行一个 return 语句,那么接下来的 else 块就没有必要了。 如果一个包含 return 语句的 else if 块,在一个包含了 return 语句的 if 块之后,那么可以拆成多个 if 块。 eslint: no-else-return
1 | // bad |
17.1 如果你的控制语句 (if, while 等) 太长或者超过了一行最大长度的限制,则可以将每个条件(或组)放入一个新的行。 逻辑运算符应该在行的开始。
为什么? 要求操作符在行的开始保持对齐并遵循类似方法衔接的模式。 这提高了可读性,并且使更复杂的逻辑更容易直观的被理解。
1 | // bad |
17.2 不要使用选择操作符代替控制语句。
1 | // bad |
18.1 使用 /** ... */ 来进行多行注释。
1 | // bad |
18.2 使用 // 进行单行注释。 将单行注释放在需要注释的行的上方新行。 在注释之前放一个空行,除非它在块的第一行。
1 | // bad |
18.3 用一个空格开始所有的注释,使它更容易阅读。 eslint: spaced-comment
1 | // bad |
18.4 使用 FIXME 或者 TODO 开始你的注释可以帮助其他开发人员快速了解,如果你提出了一个需要重新审视的问题,或者你对需要实现的问题提出的解决方案。 这些不同于其他评论,因为他们是可操作的。 这些行为是 FIXME: -- 需要解决这个问题 或者 TODO: -- 需要被实现。
18.5 使用 // FIXME: 注释一个问题。
1 | class Calculator extends Abacus { |
18.6 使用 // TODO: 注释解决问题的方法。
1 | class Calculator extends Abacus { |
19.1 使用 tabs (空格字符) 设置为 2 个空格。 eslint: indent
1 | // bad |
19.2 在主体前放置一个空格。 eslint: space-before-blocks
1 | // bad |
19.3 在控制语句(if, while 等)开始括号之前放置一个空格。 在函数调用和是声明中,在参数列表和函数名之间没有空格。 eslint: keyword-spacing
1 | // bad |
19.4 用空格分离操作符。 eslint: space-infix-ops
1 | // bad |
19.5 使用单个换行符结束文件。 eslint: eol-last
1 | // bad |
1 | // bad |
1 | // good |
19.6 在使用长方法连滴啊用的时候使用缩进(超过两个方法链)。 使用一个引导点,强调该行是方法调用,而不是新的语句。 eslint: newline-per-chained-call no-whitespace-before-property
1 | // bad |
19.7 在块和下一个语句之前留下一空白行。
1 | // bad |
19.8 不要在块的开头使用空白行。 eslint: padded-blocks
1 | // bad |
19.9 不要在括号内添加空格。 eslint: space-in-parens
1 | // bad |
19.10 不要在中括号中添加空格。 eslint: array-bracket-spacing
1 | // bad |
19.11 在花括号内添加空格。 eslint: object-curly-spacing
1 | // bad |
19.12 避免让你的代码行超过100个字符(包括空格)。 注意:根据上边的 约束,长字符串可免除此规定,不应分解。 eslint: max-len
为什么? 这样能够确保可读性和可维护性。
1 | // bad |
19.13 要求打开的块标志和同一行上的标志拥有一致的间距。此规则还会在同一行关闭的块标记和前边的标记强制实施一致的间距。 eslint: block-spacing
1 | // bad |
19.14 逗号之前避免使用空格,逗号之后需要使用空格。eslint: comma-spacing
1 | // bad |
19.15 在计算属性之间强化间距。eslint: computed-property-spacing
1 | // bad |
19.16 在函数和它的调用之间强化间距。 eslint: func-call-spacing
1 | // bad |
19.17 在对象的属性和值之间强化间距。 eslint: key-spacing
1 | // bad |
19.18 在行的末尾避免使用空格。 eslint: no-trailing-spaces
19.19 避免多个空行,并且只允许在文件末尾添加一个换行符。 eslint: no-multiple-empty-lines
1 | // bad |
20.1 逗号前置: 不行 eslint: comma-style
1 | // bad |
20.2 添加尾随逗号: 可以 eslint: comma-dangle
为什么? 这个将造成更清洁的 git 扩展差异。 另外,像 Babel 这样的编译器,会在转换后的代码中删除额外的尾随逗号,这意味着你不必担心在浏览器中后面的 尾随逗号问题 。
1 | // bad - 没有尾随逗号的 git 差异 |
1 | // bad |
为什么? 当 JavaScript 遇见一个没有分号的换行符时,它会使用一个叫做 Automatic Semicolon Insertion 的规则来确定是否应该以换行符视为语句的结束,并且如果认为如此,会在代码中断前插入一个分号到代码中。 但是,ASI 包含了一些奇怪的行为,如果 JavaScript 错误的解释了你的换行符,你的代码将会中断。 随着新特性成为 JavaScript 的一部分,这些规则将变得更加复杂。 明确地终止你的语句,并配置你的 linter 以捕获缺少的分号将有助于防止你遇到的问题。
1 | // bad - 可能异常 |
更多信息.
22.1 在语句开始前进行类型转换。
22.2 字符类型: eslint: no-new-wrappers
1 | // => this.reviewScore = 9; |
22.3 数字类型:使用 Number 进行类型铸造和 parseInt 总是通过一个基数来解析一个字符串。 eslint: radix no-new-wrappers
1 | const inputValue = '4'; |
22.4 如果出于某种原因,你正在做一些疯狂的事情,而 parseInt 是你的瓶颈,并且出于 性能问题 需要使用位运算, 请写下注释,说明为什么这样做和你做了什么。
1 | // good |
22.5 注意: 当你使用位运算的时候要小心。 数字总是被以 64-bit 值 的形式表示,但是位运算总是返回一个 32-bit 的整数 (来源)。 对于大于 32 位的整数值,位运算可能会导致意外行为。讨论。 最大的 32 位整数是: 2,147,483,647。
1 | 2147483647 >> 0; // => 2147483647 |
22.6 布尔类型: eslint: no-new-wrappers
1 | const age = 0; |
23.1 避免单字母的名字。用你的命名来描述功能。 eslint: id-length
1 | // bad |
23.2 在命名对象、函数和实例时使用驼峰命名法(camelCase)。 eslint: camelcase
1 | // bad |
23.3 只有在命名构造器或者类的时候才用帕斯卡拼命名法(PascalCase)。 eslint: new-cap
1 | // bad |
23.4 不要使用前置或者后置下划线。 eslint: no-underscore-dangle
为什么? JavaScript 在属性和方法方面没有隐私设置。 虽然前置的下划线是一种常见的惯例,意思是 “private” ,事实上,这些属性时公开的,因此,它们也是你公共 API 的一部分。 这种约定可能导致开发人员错误的认为更改不会被视为中断,或者不需要测试。建议:如果你想要什么东西是 “private” , 那就一定不能有明显的表现。
1 | // bad |
23.5 不要保存 this 的引用。 使用箭头函数或者 函数#bind。
1 | // bad |
23.6 文件名应该和默认导出的名称完全匹配。
1 | // file 1 contents |
23.7 当你导出默认函数时使用驼峰命名法。 你的文件名应该和方法名相同。
1 | function makeStyleGuide() { |
23.8 当你导出一个构造器 / 类 / 单例 / 函数库 / 暴露的对象时应该使用帕斯卡命名法。
1 | const AirbnbStyleGuide = { |
23.9 缩略词和缩写都必须是全部大写或者全部小写。
为什么? 名字是为了可读性,不是为了满足计算机算法。
1 | // bad |
23.10 你可以大写一个常亮,如果它:(1)被导出,(2)使用 const 定义(不能被重新分配),(3)程序员可以信任它(以及其嵌套的属性)是不变的。
为什么? 这是一个可以帮助程序员确定变量是否会发生变化的辅助工具。UPPERCASE_VARIABLES 可以让程序员知道他们可以相信变量(及其属性)不会改变。
- 是否是对所有的
const定义的变量? - 这个是没哟必要的,不应该在文件中使用大学。但是,它应该用于导出常量。- 导出对象呢? - 在顶级导出属性 (e.g.
EXPORTED_OBJECT.key) 并且保持所有嵌套属性不变。
1 | // bad |
24.1 对于属性的的存取函数不是必须的。
24.2 不要使用 JavaScript 的 getters/setters 方法,因为它们会导致意外的副作用,并且更加难以测试、维护和推敲。 相应的,如果你需要存取函数的时候使用 getVal() 和 setVal('hello')。
1 | // bad |
24.3 如果属性/方法是一个 boolean 值,使用 isVal() 或者 hasVal()。
1 | // bad |
24.4 可以创建 get() 和 set() 方法,但是要保证一致性。
1 | class Jedi { |
25.1 当给事件(无论是 DOM 事件还是更加私有的事件)附加数据时,传入一个对象(通畅也叫做 “hash” ) 而不是原始值。 这样可以让后边的贡献者向事件数据添加更多的数据,而不用找出更新事件的每个处理器。 例如,不好的写法:
1 | // bad |
更好的写法:
1 | // good |
26.1 对于 jQuery 对象的变量使用 $ 作为前缀。
1 | // bad |
26.2 缓存 jQuery 查询。
1 | // bad |
26.3 对于 DOM 查询使用层叠 $('.sidebar ul') 或 父元素 > 子元素 $('.sidebar > ul') 的格式。 jsPerf
26.4 对于有作用域的 jQuery 对象查询使用 find 。
1 | // bad |
标准库
包含功能已损坏的实用工具,但因为遗留原因而保留。
29.1 使用 Number.isNaN 代替全局的 isNaN.
eslint: no-restricted-globals
为什么? 全局的
isNaN强制非数字转化为数字,对任何强制转化为 NaN 的东西都返回 true。
如果需要这种行为,请明确说明。
1 | // bad |
29.2 使用 Number.isFinite 代替全局的 isFinite.
eslint: no-restricted-globals
为什么? 全局的
isFinite强制非数字转化为数字,对任何强制转化为有限数字的东西都返回 true。
如果需要这种行为,请明确说明。
1 | // bad |
map(), reduce(), and filter() optimized for traversing arrays?学习 ES6+
读这个
工具
其他编码规范
其他风格
进一步阅读
书籍
博客
播客
(The MIT License)
Copyright (c) 2012 康兵奎
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
‘Software’), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED ‘AS IS’, WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
我们鼓励您使用此指南并更改规则以适应您的团队的风格指南。下面,你可以列出一些对风格指南的修正。这允许您定期更新您的样式指南,而不必处理合并冲突。
红黑树本质上是一种二叉查找树,但它在二叉查找树的基础上额外添加了一个标记(颜色),同时具有一定的规则。这些规则使红黑树保证了一种平衡,插入、删除、查找的最坏时间复杂度都为 O(logn)。
它的统计性能要好于平衡二叉树(AVL树),因此,红黑树在很多地方都有应用。比如在 Java 集合框架中,很多部分(HashMap, TreeMap, TreeSet 等)都有红黑树的应用,这些集合均提供了很好的性能。
由于 TreeMap 就是由红黑树实现的,因此本文将使用 TreeMap 的相关操作的代码进行分析、论证。
黑色高度
从根节点到叶节点的路径上黑色节点的个数,叫做树的黑色高度。
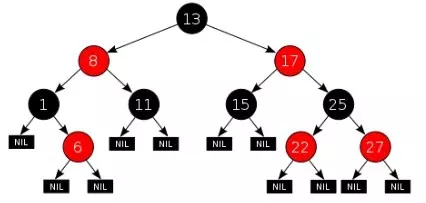
红黑树在原有的二叉查找树基础上增加了如下几个要求:
中文意思是:
注意:
性质 3 中指定红黑树的每个叶子节点都是空节点,而且并叶子节点都是黑色。但 Java 实现的红黑树将使用 null 来代表空节点,因此遍历红黑树时将看不到黑色的叶子节点,反而看到每个叶子节点都是红色的。
性质 4 的意思是:从每个根到节点的路径上不会有两个连续的红色节点,但黑色节点是可以连续的。
因此若给定黑色节点的个数 N,最短路径的情况是连续的 N 个黑色,树的高度为 N - 1;最长路径的情况为节点红黑相间,树的高度为 2(N - 1) 。
性质 5 是成为红黑树最主要的条件,后序的插入、删除操作都是为了遵守这个规定。
红黑树并不是标准平衡二叉树,它以性质 5 作为一种平衡方法,使自己的性能得到了提升。

红黑树的左右旋是比较重要的操作,左右旋的目的是调整红黑节点结构,转移黑色节点位置,使其在进行插入、删除后仍能保持红黑树的 5 条性质。
比如 X 左旋(右图转成左图)的结果,是让在 Y 左子树的黑色节点跑到 X 右子树去。
我们以 Java 集合框架中的 TreeMap 中的代码来看下左右旋的具体操作方法:
指定节点 x 的左旋 (右图转成左图):
1 | //这里 p 代表 x |
可以看到,x 节点的左旋就是把 x 变成 右孩子 y 的左孩子,同时把 y 的左孩子送给 x 当右子树。
简单点记就是:左旋把右子树里的一个节点(上图 β)移动到了左子树。
指定节点 y 的右旋(左图转成右图):
1 | private void rotateRight(Entry p) { |
同理,y 节点的右旋就是把 y 变成 左孩子 x 的右孩子,同时把 x 的右孩子送给 x 当左子树。
简单点记就是:右旋把左子树里的一个节点(上图 β)移动到了右子树。
了解左旋、右旋的方法及意义后,就可以了解红黑树的主要操作:插入、删除。
红黑树并不是真正的平衡二叉树,但在实际应用中,红黑树的统计性能要高于平衡二叉树,但极端性能略差。
红黑树的插入、删除调整逻辑比较复杂,但最终目的是满足红黑树的 5 个特性,尤其是 4 和 5。
在插入调整时为了简化操作我们直接把插入的节点涂成红色,这样只要保证插入节点的父节点不是红色就可以了。
而在删除后的调整中,针对删除黑色节点,所在子树缺少一个节点,需要进行弥补或者对别人造成一个黑色节点的伤害。具体调整方法取决于兄弟节点所在子树的情况。
红黑树的插入、删除在树形数据结构中算比较复杂的,理解起来比较难,但只要记住,红黑树有其特殊的平衡规则,而我们为了维持平衡,根据邻树的状况进行旋转或者涂色。
红黑树这么难理解,必定有其过人之处。它的有序、快速特性在很多场景下都有用到,比如 Java 集合框架的 TreeMap, TreeSet 等。
Update your browser to view this website correctly. Update my browser now