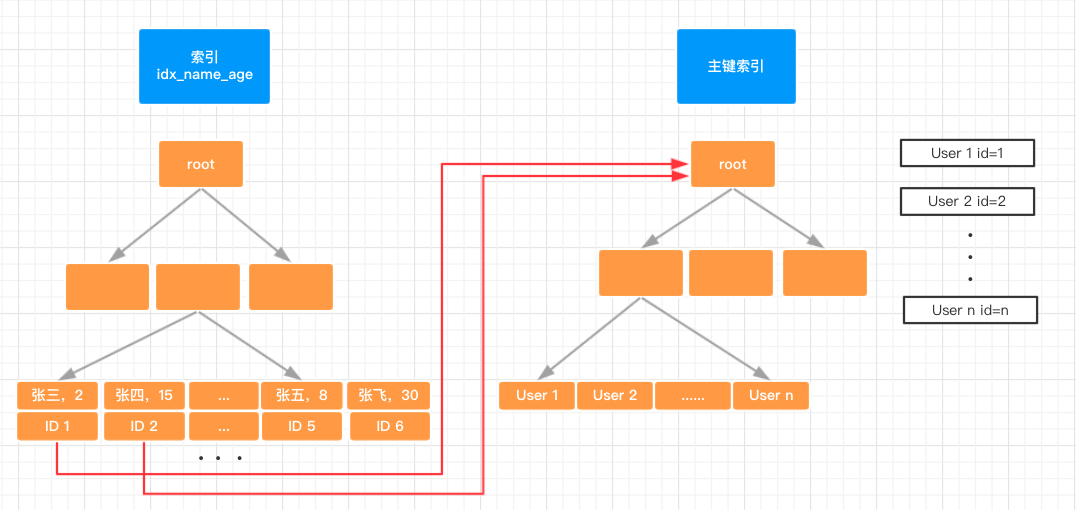
哈工大讯飞联合实验室(HFL)发布飞鹰智能文本校对系统(简称:飞鹰校对)1.0。系统针对中文文本的校对需求,提供拼写纠错、语法纠错、标点纠错及敏感词检测等功能,现已开放通用领域以及司法、教育等专用领域的智能文本校对服务。欢迎大家体验。PC端请访问:http://check.hfl-rc.com/
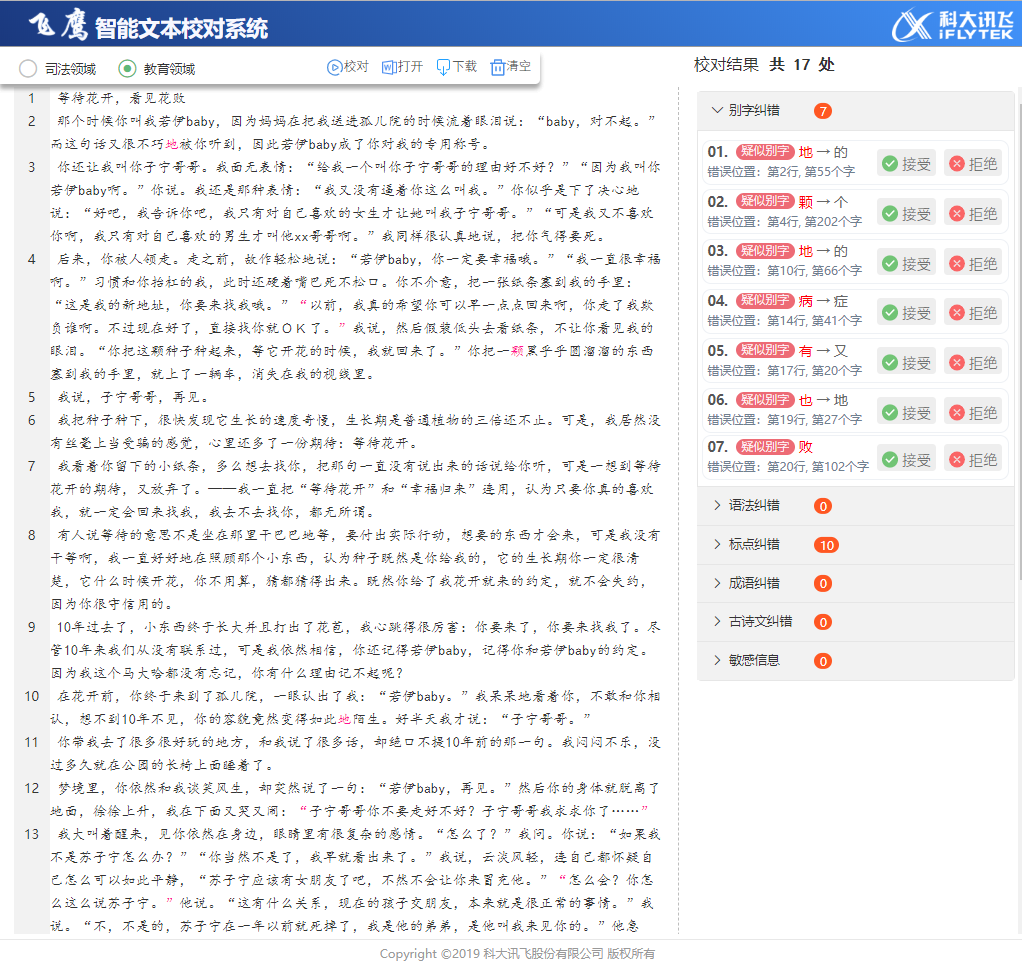
哈工大讯飞联合实验室(HFL)发布飞鹰智能文本校对系统(简称:飞鹰校对)1.0。系统针对中文文本的校对需求,提供拼写纠错、语法纠错、标点纠错及敏感词检测等功能,现已开放通用领域以及司法、教育等专用领域的智能文本校对服务。欢迎大家体验。PC端请访问:http://check.hfl-rc.com/

![]()

![]()
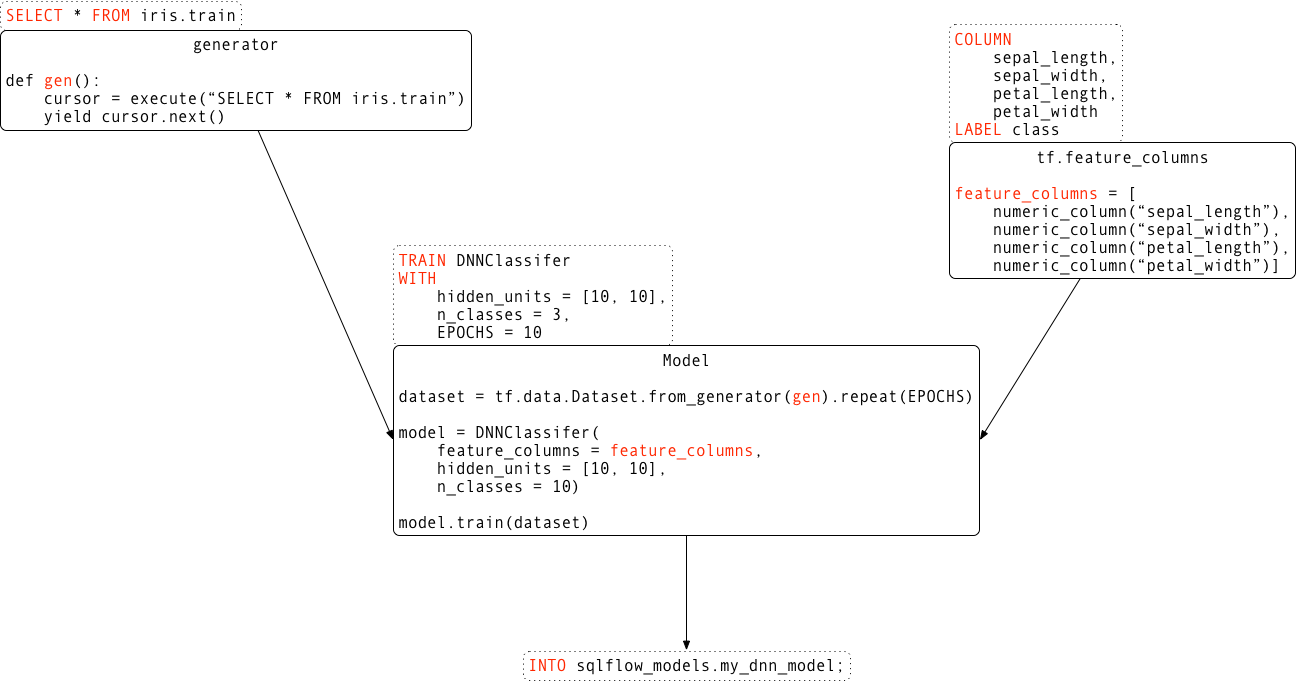
SQLFlow is a bridge that connects a SQL engine, e.g. MySQL, Hive or MaxCompute, with TensorFlow, XGBoost and other machine learning toolkits. SQLFlow extends the SQL syntax to enable model training, prediction and model explanation.

![]()
![]()
PaddlePaddle 提供了丰富的计算单元,使得用户可以采用模块化的方法解决各种学习问题。在此Repo中,我们展示了如何用 PaddlePaddle来解决常见的机器学习任务,提供若干种不同的易学易用的神经网络模型。PaddlePaddle用户可领取免费Tesla V100在线算力资源,高效训练模型,每日登陆即送12小时,连续五天运行再加送48小时,前往使用免费算力。

其实用一下图片能更好的理解LR模型和决策树模型算法的根本区别,我们可以思考一下一个决策问题:是否去相亲,一个女孩的母亲要给这个女海介绍对象。

大家都看得很明白了吧!LR模型是一股脑儿的把所有特征塞入学习,而决策树更像是编程语言中的if-else一样,去做条件判断,这就是根本性的区别。
决策树基于“树”结构进行决策的,这时我们就要面临两个问题 :
弄懂了这两个问题,那么这个模型就已经建立起来了,决策树的总体流程是“分而治之”的思想,一是自根至叶的递归过程,一是在每个中间节点寻找一个“划分”属性,相当于就是一个特征属性了。接下来我们来逐个解决以上两个问题。
在生活当中,我们都会碰到很多需要做出决策的地方,例如:吃饭地点、数码产品购买、旅游地区等,你会发现在这些选择当中都是依赖于大部分人做出的选择,也就是跟随大众的选择。其实在决策树当中也是一样的,当大部分的样本都是同一类的时候,那么就已经做出了决策。
我们可以把大众的选择抽象化,这就引入了一个概念就是纯度,想想也是如此,大众选择就意味着纯度越高。好,在深入一点,就涉及到一句话:信息熵越低,纯度越高。我相信大家或多或少都听说过“熵”这个概念,信息熵通俗来说就是用来度量包含的“信息量”,如果样本的属性都是一样的,就会让人觉得这包含的信息很单一,没有差异化,相反样本的属性都不一样,那么包含的信息量就很多了。
一到这里就头疼了,因为马上要引入信息熵的公式,其实也很简单:
Pk表示的是:当前样本集合D中第k类样本所占的比例为Pk。
信息增益
废话不多说直接上公式:

看不懂的先不管,简单一句话就是:划分前的信息熵–划分后的信息熵。表示的是向纯度方向迈出的“步长”。
好了,有了前面的知识,我们就可以开始“树”的生长了。
解释:在根节点处计算信息熵,然后根据属性依次划分并计算其节点的信息熵,用根节点信息熵–属性节点的信息熵=信息增益,根据信息增益进行降序排列,排在前面的就是第一个划分属性,其后依次类推,这就得到了决策树的形状,也就是怎么“长”了。
如果不理解的,可以查看我分享的图片示例,结合我说的,包你看懂:
不过,信息增益有一个问题:对可取值数目较多的属性有所偏好,例如:考虑将“编号”作为一个属性。为了解决这个问题,引出了另一个 算法C4.5。
为了解决信息增益的问题,引入一个信息增益率:
其中:
属性a的可能取值数目越多(即V越大),则IV(a)的值通常就越大。信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。不过有一个缺点:
使用信息增益率:基于以上缺点,并不是直接选择信息增益率最大的特征,而是现在候选特征中找出信息增益高于平均水平的特征,然后在这些特征中再选择信息增益率最高的特征。
数学家真实聪明,想到了另外一个表示纯度的方法,叫做基尼指数(讨厌的公式):

表示在样本集合中一个随机选中的样本被分错的概率。举例来说,现在一个袋子里有3种颜色的球若干个,伸手进去掏出2个球,颜色不一样的概率,这下明白了吧。Gini(D)越小,数据集D的纯度越高。
假设现在有特征 “学历”,此特征有三个特征取值: “本科”,“硕士”, “博士”,
当使用“学历”这个特征对样本集合D进行划分时,划分值分别有三个,因而有三种划分的可能集合,划分后的子集如下:
1.划分点: “本科”,划分后的子集合 : {本科},{硕士,博士}
2.划分点: “硕士”,划分后的子集合 : {硕士},{本科,博士}
3.划分点: “硕士”,划分后的子集合 : {博士},{本科,硕士}}
对于上述的每一种划分,都可以计算出基于 划分特征= 某个特征值 将样本集合D划分为两个子集的纯度:
因而对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。到此就可以长成一棵“大树”了。
ID3:取值多的属性,更容易使数据更纯,其信息增益更大。
训练得到的是一棵庞大且深度浅的树:不合理。
C4.5:采用信息增益率替代信息增益。
CART:以基尼系数替代熵,最小化不纯度,而不是最大化信息增益。
因为数值缩放不影响分裂点位置,对树模型的结构不造成影响。
按照特征值进行排序的,排序的顺序不变,那么所属的分支以及分裂点就不会有不同。而且,树模型是不能进行梯度下降的,因为构建树模型(回归树)寻找最优点时是通过寻找最优分裂点完成的,因此树模型是阶跃的,阶跃点是不可导的,并且求导没意义,也就不需要归一化。
既然树形结构(如决策树、RF)不需要归一化,那为何非树形结构比如Adaboost、SVM、LR、Knn、KMeans之类则需要归一化。
对于线性模型,特征值差别很大时,运用梯度下降的时候,损失等高线是椭圆形,需要进行多次迭代才能到达最优点。
但是如果进行了归一化,那么等高线就是圆形的,促使SGD往原点迭代,从而导致需要的迭代次数较少。
Classification And Regression Tree(CART)是决策树的一种,CART算法既可以用于创建分类树(Classification Tree),也可以用于创建回归树(Regression Tree),两者在建树的过程稍有差异。
回归树:
CART回归树是假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。
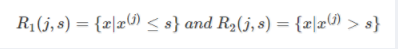
而CART回归树实质上就是在该特征维度对样本空间进行划分,而这种空间划分的优化是一种NP难问题,因此,在决策树模型中是使用启发式方法解决。典型CART回归树产生的目标函数为:
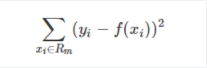
因此,当我们为了求解最优的切分特征j和最优的切分点s,就转化为求解这么一个目标函数:
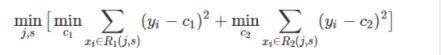
所以我们只要遍历所有特征的的所有切分点,就能找到最优的切分特征和切分点。最终得到一棵回归树。
决策树的剪枝基本策略有 预剪枝 (Pre-Pruning) 和 后剪枝 (Post-Pruning)。
参考文章:决策树及决策树生成与剪枝
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
欢迎大家加入讨论!共同完善此项目!群号:【541954936】
过去一年中,我们比较了近22000个机器学习开源工程,并筛选了49个顶级项目(筛选率0.22%)。
其中包括以下6个分类
我们花了很大的精力筛选这个list,并小心的选择出2018年1月到12月间最好的工程。为了保证名单质量,Mybridge AI协同考虑了流行度、参与度、发布时间等多重因素。
计算机视觉
1、Detectron:facebook发布的目标检测工具【18913 star on Github】
项目地址:
https://github.com/facebookresearch/Detectron?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

2、Openpost:多人实时特征点检测工具【11052 stars on GitHub】
项目地址:
https://github.com/CMU-Perceptual-Computing-Lab/openpose?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

3、DensePost:2维人体图片转3维的实时映射方法。【4165 stars on Github】
项目地址:
https://github.com/facebookresearch/Densepose?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

4、Maskrcnn-benchmark:(Pytorch)语义分割与目标检测工具包。【3888 stars on Github】
项目地址:
https://github.com/facebookresearch/maskrcnn-benchmark?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

5、SNIPER:多尺度目标检测算法。【1963 stars on Github】
项目地址:
https://github.com/mahyarnajibi/SNIPER?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

强化学习
6、Psychlab:Psychlab实验范例。【5595 stars on Github】
项目地址:
https://github.com/deepmind/lab/tree/master/game_scripts/levels/contributed/psychlab?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
7、ELF:一个灵活、轻量、可扩展的游戏研究平台。【2406 stars on Github】
项目地址:
https://github.com/pytorch/elf?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
8、TRFL:(TensorFlow)强化学习agent工具包。【2312 stars on Github】
项目地址:
https://github.com/deepmind/trfl?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
9、Horizon:首个用于大规模需求的开源强化学习平台。【1703 stars on Github】
项目地址:
https://github.com/facebookresearch/Horizon?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
10、Chess-alpha-zero:国际象棋强化学习项目(基于AlphaGo Zero方法)。【1307 stars on Github】
项目地址:
https://github.com/Zeta36/chess-alpha-zero?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
11、Dm_control:DeepMind工具包。【1231 stars on Github】
项目地址:
https://github.com/deepmind/dm_control?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
12、MAMEToolkit:基于强化学习的电子游戏python库。【437 stars on Github】
项目地址:
https://github.com/M-J-Murray/MAMEToolkit?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
13、Reaver:模块化的深度强化学习框架(星际争霸2)。【355 stars on Github】
项目地址:
https://github.com/inoryy/reaver?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
NLP
14、Bert:BERT的TensorFlow代码,以及预训练模型。【11703 stars on Github】
项目地址:
https://github.com/google-research/bert?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
15、Pytext:基于Pytorch的神经语言模型框架。【4466 stars on Github】
项目地址:
https://github.com/facebookresearch/pytext?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
16、Bert-as-service:BERT模型的网络服务版本
项目地址:
https://github.com/hanxiao/bert-as-service?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
17、UnsupervisedMT:基于Phrase的无监督机器翻译方法。【1068 stars on Github】
项目地址:
https://github.com/facebookresearch/UnsupervisedMT?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
18、DecaNLP:NLP十项全能工具,多任务模型。【1648 stars on Github】
项目地址:
https://github.com/salesforce/decaNLP?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
19、NLP-architect:来自英特尔AI实验室的python工具包,包含了当前NLP领域的多种最佳模型。【1751 stars on Github】
项目地址:
https://github.com/NervanaSystems/nlp-architect?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
20、Gluon-nlp:NLP工具包。【1263 stars on Github】
项目地址:
https://github.com/dmlc/gluon-nlp?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
GAN
21、DeOldify:一个基于深度学习的图像补全工具包。【5060 stars on Github】
项目地址:
https://github.com/jantic/DeOldify?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
22、Progressive_growing_of_gans:GAN的变种实现,提高生产质量、稳定性以及多样性。
项目地址:
https://github.com/tkarras/progressive_growing_of_gans?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
23、MUNIT:多模态无监督图像翻译。【1339 stars on Github】
项目地址:
https://github.com/NVlabs/MUNIT?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
24、Transparent_latent_gan:使用监督学习来解释GAN的隐空间信息。【1337 stars on Github】
项目地址:
https://github.com/SummitKwan/transparent_latent_gan?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
25、Gandissect:基于Pytorch的可视化以及理解GAN的神经元信息。【1065 stars on Github】
项目地址:
https://github.com/CSAILVision/gandissect?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
26、GANimation:单张图片的表情变换。【869 stars on Github】
项目地址:
https://github.com/albertpumarola/GANimation?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
神经网络
27、Fastai:加速神经网络训练过程,并提高准确率。【11597 stars on Github】
项目地址:
https://github.com/fastai/fastai?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
28、DeepCreamPy:图像修复。【7046 stars on Github】
项目地址:
https://github.com/deeppomf/DeepCreamPy?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
29、Augmentor v0.2、图像增强工具包。【2805 stars on Github】
项目地址:
https://github.com/mdbloice/Augmentor?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
30、Graph_nets:Tensorflow的图网络构建工具。【2723 stars on Github】
项目地址:
https://github.com/deepmind/graph_nets?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
31、Textgenrnn:使用预训练字符级RNN生成文本。【1900 stars on Github】
项目地址:
https://github.com/minimaxir/textgenrnn?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
32、Person-blocker:图像中自动删除人像。【1806 stars on Github】
项目地址:
https://github.com/minimaxir/person-blocker?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
33、Deepvariant:DNA序列数据的分析工具
项目地址:
https://github.com/google/deepvariant?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
34、Video-nolocal-net:non-local神经网络的视频分类方法。【1049 stars on Github】
项目地址:
https://github.com/facebookresearch/video-nonlocal-net?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
35、Ann-visualizer:神经网络可视化工具。【922 stars on Github】
项目地址:
https://github.com/Prodicode/ann-visualizer?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
工具包
36、Tfjs:一个基于JS的ML模型训练部署工具包。【10268 stars on Github】
项目地址:
https://github.com/tensorflow/tfjs?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
37:Dopamine:快速的强化学习研究框架。【7142 stars on Github】
项目地址:
https://github.com/google/dopamine?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
38、Lime:分类器解释工具包。【5173 stars on Github】
项目地址:
https://github.com/marcotcr/lime?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
39、Autokeras:自动机器学习的开源软件库。【4520 stars on Github】
项目地址:
https://github.com/jhfjhfj1/autokeras?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
40、Shap:神经网络解释工具。【3496 stars on Github】
项目地址:
https://github.com/slundberg/shap?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
41、MMdnn:模型适配器。【3021 stars on Github】
项目地址:
https://github.com/Microsoft/MMdnn?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
42、Mlflow:机器学习生命周期管理。【3013 stars on Github】
项目地址:
https://github.com/mlflow/mlflow?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
43、Mace:面向移动计算平台的深度学习推断框架。【2979 stars on Github】
项目地址:
https://github.com/XiaoMi/mace?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
44、PySyft:关注安全性的深度学习库。【2595 stars on Github】
项目地址:
https://github.com/OpenMined/PySyft?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
45、Adanet:AutoML计算库。【2293 stars on Github】
项目地址:
https://github.com/tensorflow/adanet?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
46、Tencent-ml-images:最大的多标签图像数据库。【2094 stars on Github】
项目地址:
https://github.com/Tencent/tencent-ml-images?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
47、Donkeycar、开源的软硬件自动驾驶平台。【1207 stars on Github】
项目地址:
https://github.com/autorope/donkeycar?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
48、PocketFlow:自动模型压缩框架。【1677 stars on Github】
项目地址:
https://github.com/Tencent/PocketFlow?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
49、DALI:深度学习应用的优化工具包以及数据处理扩展引擎。【1013 stars on Github】
项目地址:
https://github.com/NVIDIA/dali?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
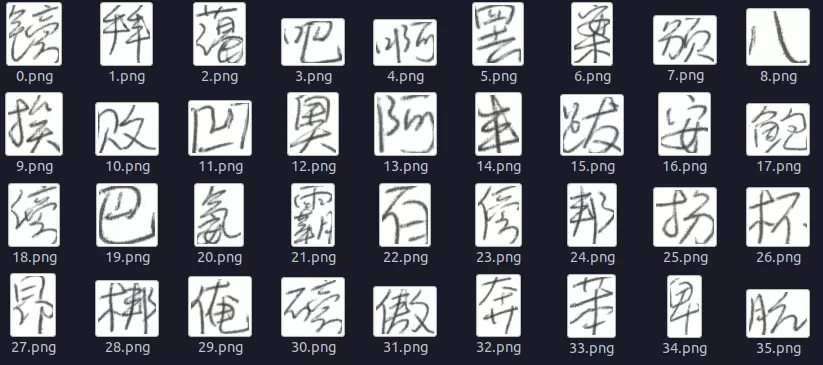
在开始之前,先介绍一下本项目所采用的数据信息。我们的数据全部来自于CASIA的开源中文手写字数据集,该数据集分为两部分:
其实你下载1.0的train和test差不多已经够了,可以直接运行 dataset/get_hwdb_1.0_1.1.sh 下载。原始数据下载链接点击这里. 由于原始数据过于复杂,我们使用一个类来封装数据读取过程,这是我们展示的效果:
看到这么密密麻麻的文字相信连人类都…. 开始头疼了,这些复杂的文字能够通过一个神经网络来识别出来??答案是肯定的…. 不有得感叹一下神经网络的强大。。上面的部分文字识别出来的结果是这样的:

关于数据的处理部分,从服务器下载到的原始数据是 trn_gnt.zip 解压之后是 gnt.alz, 需要再次解压得到一个包含 gnt文件的文件夹。里面每一个gnt文件都包含了若干个汉字及其标注。直接处理比较麻烦,也不方便抽取出图片再进行操作,虽然转为图片存入文件夹比较直观,但是不适合批量读取和训练, 后面我们统一转为tfrecord进行训练。
更新: 实际上,由于单个汉字图片其实很小,差不多也就最大80x80的大小,这个大小不适合转成图片保存到本地,因此我们将hwdb原始的二进制保存为tfrecord。同时也方便后面训练,可以直接从tfrecord读取图片进行训练。
1 | def train(): |
大家在以后编写训练代码的时候其实可以保持这个好的习惯。
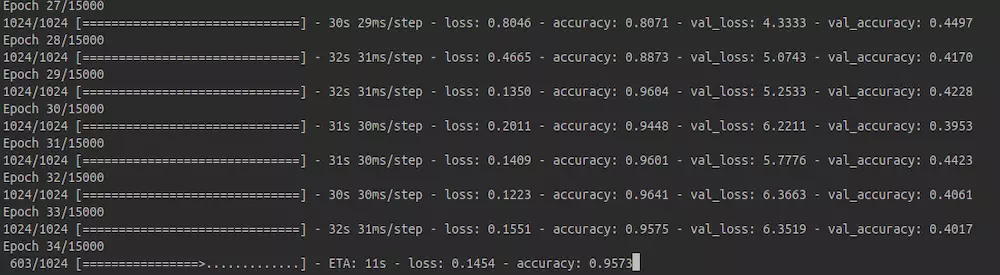
OK,整个模型训练起来之后,可以在短时间内达到95%的准确率:
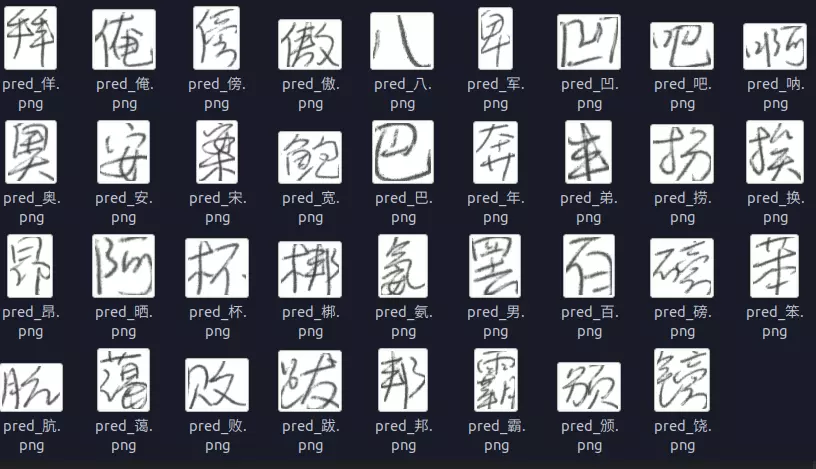
通过本教程,我们完成了使用tensorflow 2.0全新的API搭建一个中文汉字手写识别系统。模型基本能够实现我们想要的功能。要知道,这个模型可是在搜索空间多大3755的类别当中准确的找到最相似的类别!!通过本实验,我们有几点心得:
Update your browser to view this website correctly. Update my browser now