PLMpapers
Contributed by Xiaozhi Wang and Zhengyan Zhang.
Introduction
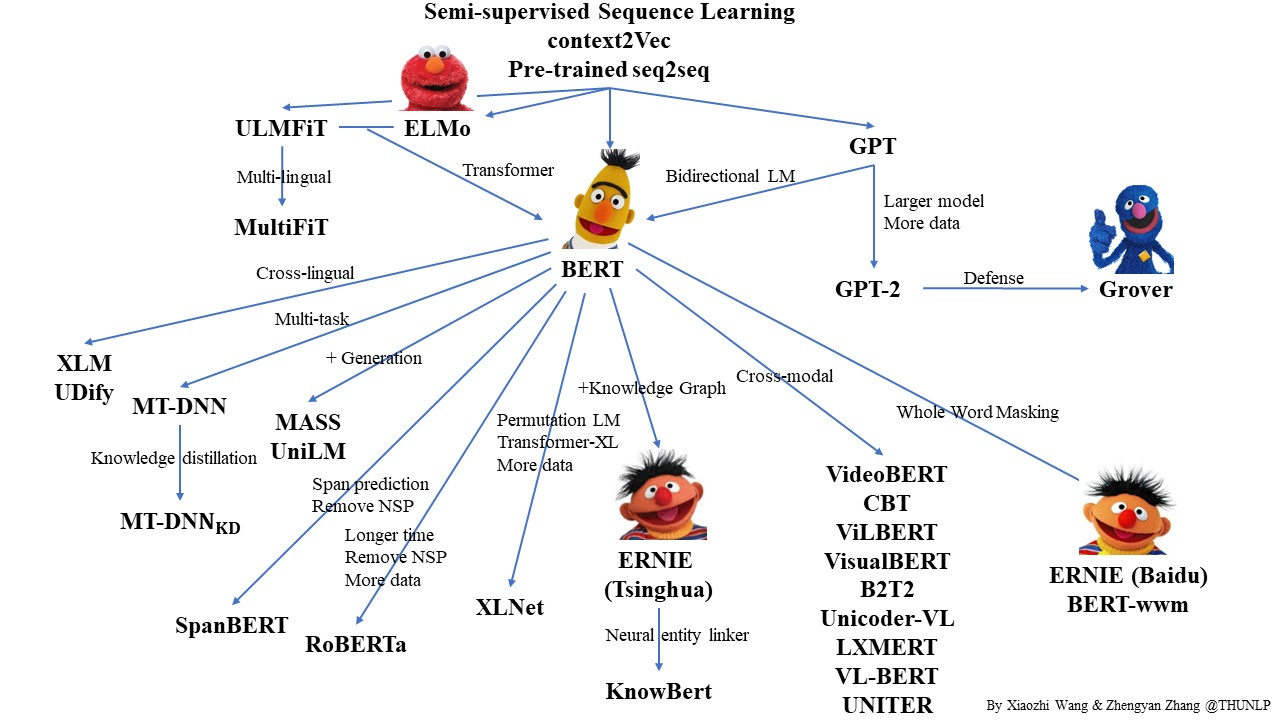
Pre-trained Languge Model (PLM) is a very popular topic in NLP. In this repo, we list some representative work on PLM and show their relationship with a diagram. Feel free to distribute or use it! Here you can get the source PPT file of the diagram if you want to use it in your presentation.
Corrections and suggestions are welcomed.
We also released OpenCLap, an open-source Chinese language pre-trained model zoo. Welcome to try it.
Papers
Models
- Semi-supervised Sequence Learning. Andrew M. Dai, Quoc V. Le. NIPS 2015. [pdf]
- context2vec: Learning Generic Context Embedding with Bidirectional LSTM. Oren Melamud, Jacob Goldberger, Ido Dagan. CoNLL 2016. [pdf] [project] (context2vec)
- Unsupervised Pretraining for Sequence to Sequence Learning. Prajit Ramachandran, Peter J. Liu, Quoc V. Le. EMNLP 2017. [pdf] (Pre-trained seq2seq)`
- Deep contextualized word representations. Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee and Luke Zettlemoyer. NAACL 2018. [pdf] [project] (ELMo)
- Universal Language Model Fine-tuning for Text Classification. Jeremy Howard and Sebastian Ruder. ACL 2018. [pdf] [project] (ULMFiT)
- Improving Language Understanding by Generative Pre-Training. Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever. Preprint. [pdf] [project] (GPT)
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. NAACL 2019. [pdf] [code & model]
- Language Models are Unsupervised Multitask Learners. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever. Preprint. [pdf] [code] (GPT-2)
- ERNIE: Enhanced Language Representation with Informative Entities. Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun and Qun Liu. ACL 2019. [pdf] [code & model] (ERNIE (Tsinghua) )
- ERNIE: Enhanced Representation through Knowledge Integration. Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian and Hua Wu. Preprint. [pdf] [code] (ERNIE (Baidu) )
- Defending Against Neural Fake News. Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, Yejin Choi. NeurIPS 2019. [pdf] [project] (Grover)
- Cross-lingual Language Model Pretraining. Guillaume Lample, Alexis Conneau. NeurIPS 2019. [pdf] [code & model] (XLM)
- Multi-Task Deep Neural Networks for Natural Language Understanding. Xiaodong Liu, Pengcheng He, Weizhu Chen, Jianfeng Gao. ACL 2019. [pdf] [code & model] (MT-DNN)
- MASS: Masked Sequence to Sequence Pre-training for Language Generation. Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu. ICML 2019. [pdf] [code & model]
- Unified Language Model Pre-training for Natural Language Understanding and Generation. Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon. Preprint. [pdf] (UniLM)
- XLNet: Generalized Autoregressive Pretraining for Language Understanding. Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le. NeurIPS 2019. [pdf] [code & model]
- RoBERTa: A Robustly Optimized BERT Pretraining Approach. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. Preprint. [pdf] [code & model]
- SpanBERT: Improving Pre-training by Representing and Predicting Spans. Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy. Preprint. [pdf] [code & model]
- Knowledge Enhanced Contextual Word Representations. Matthew E. Peters, Mark Neumann, Robert L. Logan IV, Roy Schwartz, Vidur Joshi, Sameer Singh, Noah A. Smith. EMNLP 2019. [pdf] (KnowBert)
- VisualBERT: A Simple and Performant Baseline for Vision and Language. Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang. Preprint. [pdf] [code & model]
- ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee. NeurIPS 2019. [pdf] [code & model]
- VideoBERT: A Joint Model for Video and Language Representation Learning. Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, Cordelia Schmid. ICCV 2019. [pdf]
- LXMERT: Learning Cross-Modality Encoder Representations from Transformers. Hao Tan, Mohit Bansal. EMNLP 2019. [pdf] [code & model]
- VL-BERT: Pre-training of Generic Visual-Linguistic Representations. Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. Preprint. [pdf]
- Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training. Gen Li, Nan Duan, Yuejian Fang, Ming Gong, Daxin Jiang, Ming Zhou. Preprint. [pdf]
- K-BERT: Enabling Language Representation with Knowledge Graph. Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Qi Ju, Haotang Deng, Ping Wang. Preprint. [pdf]
- Fusion of Detected Objects in Text for Visual Question Answering. Chris Alberti, Jeffrey Ling, Michael Collins, David Reitter. EMNLP 2019. [pdf] (B2T2)
- Contrastive Bidirectional Transformer for Temporal Representation Learning. Chen Sun, Fabien Baradel, Kevin Murphy, Cordelia Schmid. Preprint. [pdf] (CBT)
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding. Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu, Haifeng Wang. Preprint. [pdf] [code]
- 75 Languages, 1 Model: Parsing Universal Dependencies Universally. Dan Kondratyuk, Milan Straka. EMNLP 2019. [pdf] [code & model] (UDify)
- Pre-Training with Whole Word Masking for Chinese BERT. Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu. Preprint. [pdf] [code & model] (Chinese-BERT-wwm)
- UNITER: Learning UNiversal Image-TExt Representations. Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, Jingjing Liu. Preprint. [pdf]
- HUBERT Untangles BERT to Improve Transfer across NLP Tasks. Anonymous authors. ICLR 2020 under review. [pdf]
- MultiFiT: Efficient Multi-lingual Language Model Fine-tuning. Julian Eisenschlos, Sebastian Ruder, Piotr Czapla, Marcin Kardas, Sylvain Gugger, Jeremy Howard. EMNLP 2019. [pdf] [code & model]
Knowledge Distillation & Model Compression
- TinyBERT: Distilling BERT for Natural Language Understanding. Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu. Preprint. [pdf]
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks. Raphael Tang, Yao Lu, Linqing Liu, Lili Mou, Olga Vechtomova, Jimmy Lin. Preprint. [pdf]
- Patient Knowledge Distillation for BERT Model Compression. Siqi Sun, Yu Cheng, Zhe Gan, Jingjing Liu. EMNLP 2019. [pdf] [code]
- Model Compression with Multi-Task Knowledge Distillation for Web-scale Question Answering System. Ze Yang, Linjun Shou, Ming Gong, Wutao Lin, Daxin Jiang. Preprint. [pdf]
- PANLP at MEDIQA 2019: Pre-trained Language Models, Transfer Learning and Knowledge Distillation. Wei Zhu, Xiaofeng Zhou, Keqiang Wang, Xun Luo, Xiepeng Li, Yuan Ni, Guotong Xie. The 18th BioNLP workshop. [pdf]
- Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding. Xiaodong Liu, Pengcheng He, Weizhu Chen, Jianfeng Gao. Preprint. [pdf] [code & model]
- Well-Read Students Learn Better: The Impact of Student Initialization on Knowledge Distillation. Iulia Turc, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. Preprint. [pdf]
- Small and Practical BERT Models for Sequence Labeling. Henry Tsai, Jason Riesa, Melvin Johnson, Naveen Arivazhagan, Xin Li, Amelia Archer. EMNLP 2019. [pdf]
- Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT. Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W. Mahoney, Kurt Keutzer. Preprint. [pdf]
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. Anonymous authors. ICLR 2020 under review. [pdf]
- Extreme Language Model Compression with Optimal Subwords and Shared Projections. Sanqiang Zhao, Raghav Gupta, Yang Song, Denny Zhou. Preprint. [pdf]
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf. Preprint. [pdf]
Analysis
- Revealing the Dark Secrets of BERT. Olga Kovaleva, Alexey Romanov, Anna Rogers, Anna Rumshisky. EMNLP 2019. [pdf]
- How Does BERT Answer Questions? A Layer-Wise Analysis of Transformer Representations. Betty van Aken, Benjamin Winter, Alexander Löser, Felix A. Gers. CIKM 2019. [pdf]
- Are Sixteen Heads Really Better than One?. Paul Michel, Omer Levy, Graham Neubig. Preprint. [pdf] [code]
- Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment. Di Jin, Zhijing Jin, Joey Tianyi Zhou, Peter Szolovits. Preprint. [pdf] [code]
- BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model. Alex Wang, Kyunghyun Cho. NeuralGen 2019. [pdf] [code]
- Linguistic Knowledge and Transferability of Contextual Representations. Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, Noah A. Smith. NAACL 2019. [pdf]
- What Does BERT Look At? An Analysis of BERT’s Attention. Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning. BlackBoxNLP 2019. [pdf] [code]
- Open Sesame: Getting Inside BERT’s Linguistic Knowledge. Yongjie Lin, Yi Chern Tan, Robert Frank. BlackBoxNLP 2019. [pdf] [code]
- Analyzing the Structure of Attention in a Transformer Language Model. Jesse Vig, Yonatan Belinkov. BlackBoxNLP 2019. [pdf]
- Blackbox meets blackbox: Representational Similarity and Stability Analysis of Neural Language Models and Brains. Samira Abnar, Lisa Beinborn, Rochelle Choenni, Willem Zuidema. BlackBoxNLP 2019. [pdf]
- BERT Rediscovers the Classical NLP Pipeline. Ian Tenney, Dipanjan Das, Ellie Pavlick. ACL 2019. [pdf]
- How multilingual is Multilingual BERT?. Telmo Pires, Eva Schlinger, Dan Garrette. ACL 2019. [pdf]
- What Does BERT Learn about the Structure of Language?. Ganesh Jawahar, Benoît Sagot, Djamé Seddah. ACL 2019. [pdf]
- Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT. Shijie Wu, Mark Dredze. EMNLP 2019. [pdf]
- How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. Kawin Ethayarajh. EMNLP 2019. [pdf]
- Probing Neural Network Comprehension of Natural Language Arguments. Timothy Niven, Hung-Yu Kao. ACL 2019. [pdf] [code]
- Universal Adversarial Triggers for Attacking and Analyzing NLP. Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, Sameer Singh. EMNLP 2019. [pdf] [code]
- The Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives. Elena Voita, Rico Sennrich, Ivan Titov. EMNLP 2019. [pdf]
- Do NLP Models Know Numbers? Probing Numeracy in Embeddings. Eric Wallace, Yizhong Wang, Sujian Li, Sameer Singh, Matt Gardner. EMNLP 2019. [pdf]
- Investigating BERT’s Knowledge of Language: Five Analysis Methods with NPIs. Alex Warstadt, Yu Cao, Ioana Grosu, Wei Peng, Hagen Blix, Yining Nie, Anna Alsop, Shikha Bordia, Haokun Liu, Alicia Parrish, Sheng-Fu Wang, Jason Phang, Anhad Mohananey, Phu Mon Htut, Paloma Jeretič, Samuel R. Bowman. EMNLP 2019. [pdf] [code]
- Visualizing and Understanding the Effectiveness of BERT. Yaru Hao, Li Dong, Furu Wei, Ke Xu. EMNLP 2019. [pdf]
- Visualizing and Measuring the Geometry of BERT. Andy Coenen, Emily Reif, Ann Yuan, Been Kim, Adam Pearce, Fernanda Viégas, Martin Wattenberg. NeurIPS 2019. [pdf]
- On the Validity of Self-Attention as Explanation in Transformer Models. Gino Brunner, Yang Liu, Damián Pascual, Oliver Richter, Roger Wattenhofer. Preprint. [pdf]
- Transformer Dissection: An Unified Understanding for Transformer’s Attention via the Lens of Kernel. Yao-Hung Hubert Tsai, Shaojie Bai, Makoto Yamada, Louis-Philippe Morency, Ruslan Salakhutdinov. EMNLP 2019. [pdf]
- Language Models as Knowledge Bases? Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel. EMNLP 2019, [pdf] [code]
- To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks. Matthew E. Peters, Sebastian Ruder, Noah A. Smith. RepL4NLP 2019, [pdf]
Tutorial & Resource
- Transfer Learning in Natural Language Processing. Sebastian Ruder, Matthew E. Peters, Swabha Swayamdipta, Thomas Wolf. NAACL 2019. [slides]
- Transformers: State-of-the-art Natural Language Processing. Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Jamie Brew. Preprint. [pdf] [code]