数据库备份恢复容器化项目实践经验总结
本文分享了唯品会数据库Docker的异地容灾项目实践经验,项目中针对用户数据库的异地恢复场景的需求进行开发和测试,整合了网络,存储、调度、监控,镜像等多个模块。在实施完成后,从技术上总结关于选型、开发、踩坑、测试等方面的经验。
项目背景
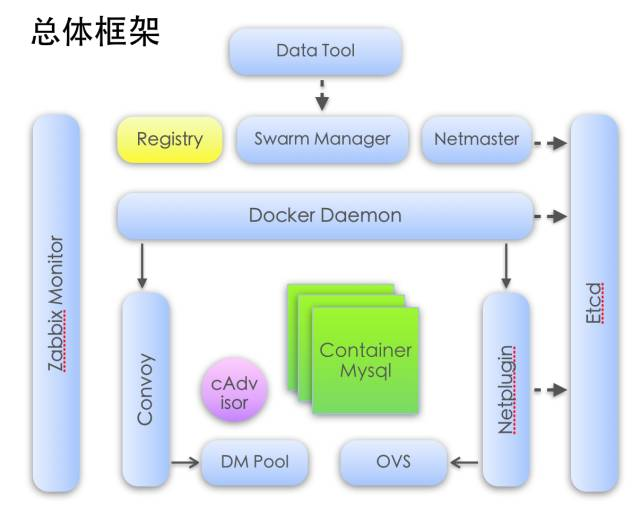
数据库Docker的异地备份恢复容灾项目,针对用户数据库的异地备份恢复场景的需求进行开发和测试,整合了容器网络、存储、调度、监控、镜像等多个模块。同时针对数据库的日常运维工作开发了监控、资源调度、日志、Puppet自动推送等工具。
通过Docker天生隔离性和快速部署等特点,实现在单台物理机上运行多个数据库备份/恢复实例,大大提高服务器使用率,节省大量成本。通过对Docker本身和相关组件的研究和改造,从普通开源产品落地到公司内部生产环境,积累宝贵的开发经验。通过对Docker已经在其上层运行的数据库日常运维和监控,也积累宝贵的Docker运维经验,为更大规模推广容器提供基础。
关于容器技术
通过实践,证明容器技术在易用性,可管理性,快速部署具备天然的优势。在资源利用率方面,容器部署在上百个物理节点上,提供约500多个数据库灾备实例,提升了硬件资源的利用率,节约了约400台物理机的采购成本。这些是容器技术带来的实实在在收益。在资源分配与隔离方面,又不输于虚拟机。CPU、内存、磁盘IO、网络IO限流等技术的应用,保证了资源的合理使用,从机制上阻止了单一实例的资源过分消耗的问题。
稳定性是使用容器技术非常关注的一个点,也是基石。MySQL备份/恢复属于CPU密集 + 磁盘IO密集 + 网络IO密集型业务,对于Docker daemon是个较大的考验。就目前来看,限制每台宿主机的容器数量(5个左右)的情况下,集群跑了三个多月没有出现因为容器负载过大导致的crash现象,还是值得信赖的。遇到的唯一相关问题是Docker daemon挂死,具体现象是docker info、docker ps没有响应,docker volume、docker images 正常,下面的容器运行正常。这是偶发事件,无法重现,以后需要继续观察。
由于容器以进程方式存在,体现出几乎与物理机上相当的性能,Overheads极低(低于10%)。从数据抽取任务的结果来看,与物理机相比,使用容器对成功率没有影响,效率也差不多。这也很符合最初预想,不管跑容器还是外部服务从物理机角度来说它们之间是没有什么区别的,都是一个进程,唯一不同是父进程不一样而已。
以上是容器“RUN”带来的好处,通过统一开发流程,应用微服务化,CI/CD等方面的改进,能够进一步利用容器“BUILD”、“SHIP” 优势,容器技术还来的潜力是巨大的。要说容器技术的缺点,还真的不明显。硬要提的话一个是需要一定的学习成本,改变开发流程与方式,一个是开发人员对容器技术的接受程度。这个项目仅用了不到二百人/天,对于一个采用新技术的项目来说,真的是很低的了。一开始我们也担心因为采用新技术导致开发推广有困难,后来实际能通过技术上解决问题,打消了大部分用户对使用Docker的疑虑,反而有助于该技术的普遍应用。
关于Docker daemon版本的选择,我们之前是有过一些讨论的。现在Docker社区非常活跃,当时我们用1.10.3, 到现在已经出了两个新版本了。在功能满足的前提下,稳定性是第一考量。Docker自1.9.0引入CNM网络模型,1.10算是比较成熟。CNM是我们希望在这个项目尝试的一部分。网络与Volume插件功能与稳定性的提升,开始支持磁盘IO读写限速,Device Mapper的支持,等等,都是选择了这个版本的原因。另外,Docker插件的引入,很好地解耦了Docker与底层模块的关系,使我们可以专注于底层(网络、存储)实现而不需要修改Docker daemon本身,同时避免产生升级依赖。
关于容器存储
容器外部卷使用Convoy,以插件的形式支持容器持久化数据。容器本身与外部卷均使用Device Mapper作为底层。没有选择分布式存储原因,主要是为了简化实现,更稳定。通过限制每个容器的BlkioDeviceReadBps、BlkioDeviceWriteBps、BlkioDeviceReadIOps、BlkioDeviceWriteIOps,使磁盘IO稳定地达到相当于95%物理机性能。
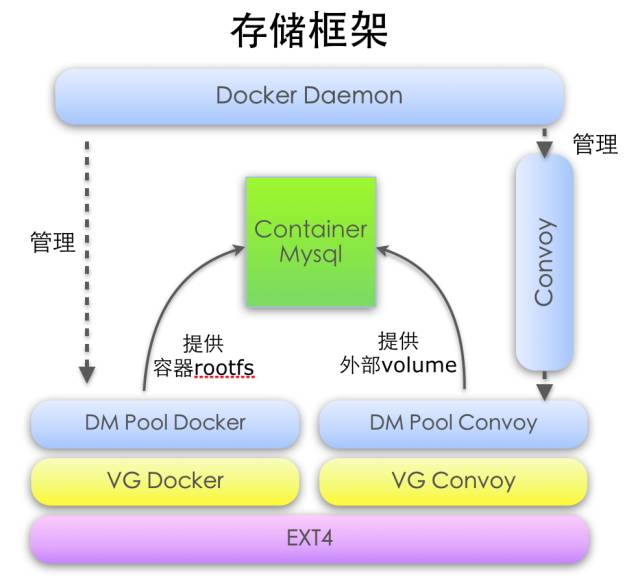
对于Device Mapper,因为是红帽推荐的,而OS又是用的CentOS7.2, 所以就用了它。测试过程中发现Device Mapper健壮性不是很好,仅仅在低并发下,也会出现容器删除失败的情况,容器并发启停偶尔出现找不到设备的情况。这种使用映射关系的设备,功能是丰富,实现上过于复杂,每次对设备的修改都需要额外去更新Metadata,并发场景出错的机会就大了。让我再选的话我会考虑Overlay这种更简单的driver。
对于Convoy,是来自Rancher的产品,Go语言,仍然处于未成熟阶段,版本号0.5, 并没有完全实现Volume Plugin接口。相比其它模块它的问题也是最多的,例如Volume创建失败,无法删除,UNIX Socket泄漏,重名冲突,异常自动退出等。属于能用,但未完善的状态,你自己得有一定开发调试能力去解决发现的问题。其它几个存储插件情况也差不多,Flocker、Blockbridge、Horcrux等等,有的连第一个正式发布版都还没有,Convoy反而相对好点,有点烂柿子堆里挑的感觉。
关于容器监控
容器监控在这个项目里还可以有很大的空间可以改进。项目里用的是cAdvisor,容器内top、free、iostat命令劫持,基于已有的Zabbix体系作数据收集与展示。结论是Zabbix完全不合适做容器监控,数据收集密度,展示质量,灵活度都没能满足需求。
后来在测试中尝试使用Telegraf + InfluxDB + Grafana。 只需要Grafana简单的配置,能够帮忙我们清晰地展示容器及服务进程CPU、内存、网络、磁盘等情况。Grafana上SQL查询语句的调试与开发,确实需要不少的时间,但这个工作量是一次性的。因为是Go写的,Telegraf CPU占用属于比较低的水平(0.4 – 5%)。功能上比较丰富,同时支持外部进程与容器的数据收集,多达55种数据源插件,有它就不需要布cAdvisor了,个人比较推荐。需要告警的同学,可以考虑把influxDB改成Prometheus。它包含Alertmanager实现Email、PagerDuty等消息通知。数据Backend可以选择自带的DB,也可以外接influxDB、Graphite、OpenTSDB等流行方案。
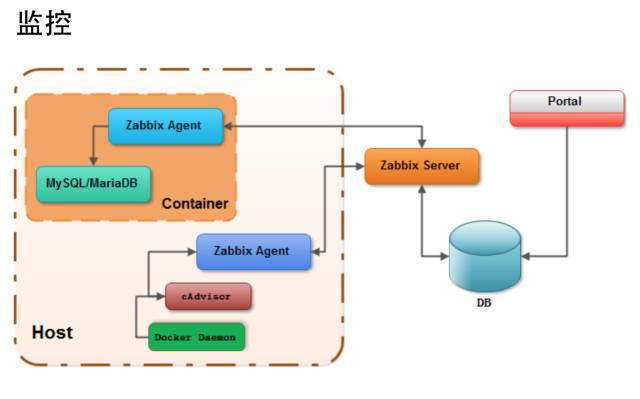
监控领域业界已经有很多开源方案可以参考,以下是要衡量的标准:易扩展、开销低、入侵小、大集中、易部署、实时性、展现清晰灵活。这方面希望与各位有更多的交流。