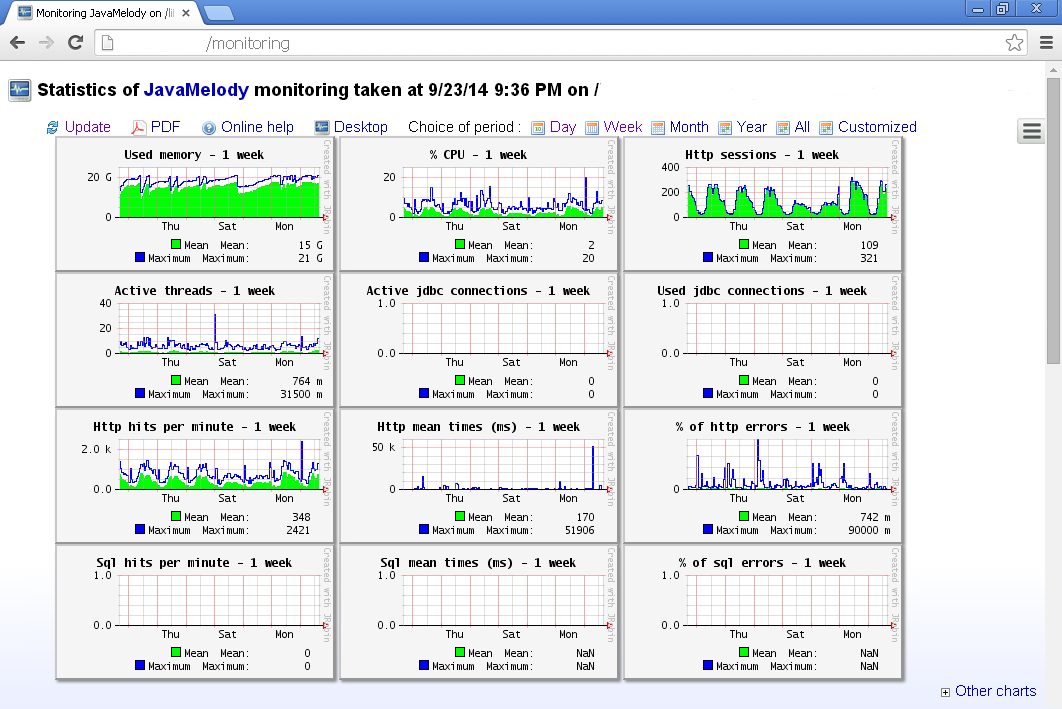
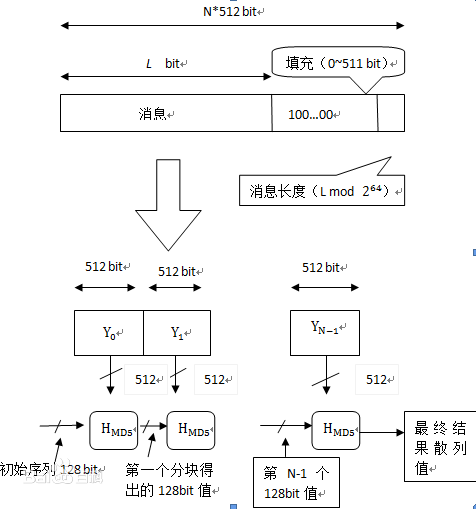
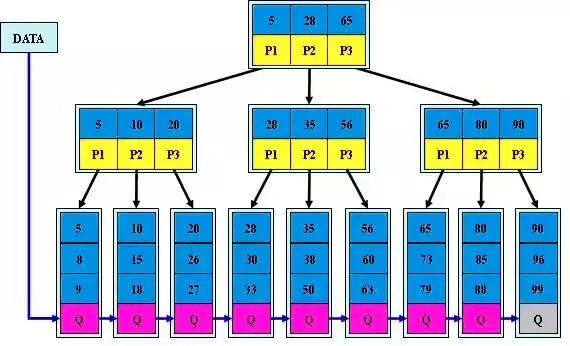
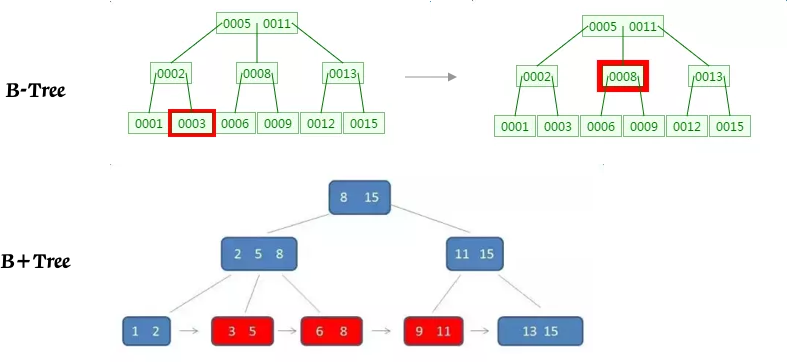
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
| #include<iostream>
#include<string>
using namespace std;
#define shift(x, n) (((x) << (n)) | ((x) >> (32-(n))))//右移的时候,高位一定要补零,而不是补充符号位
#define F(x, y, z) (((x) & (y)) | ((~x) & (z)))
#define G(x, y, z) (((x) & (z)) | ((y) & (~z)))
#define H(x, y, z) ((x) ^ (y) ^ (z))
#define I(x, y, z) ((y) ^ ((x) | (~z)))
#define A 0x67452301
#define B 0xefcdab89
#define C 0x98badcfe
#define D 0x10325476
unsigned int strlength;
unsigned int atemp;
unsigned int btemp;
unsigned int ctemp;
unsigned int dtemp;
const unsigned int k[]={
0xd76aa478,0xe8c7b756,0x242070db,0xc1bdceee,
0xf57c0faf,0x4787c62a,0xa8304613,0xfd469501,0x698098d8,
0x8b44f7af,0xffff5bb1,0x895cd7be,0x6b901122,0xfd987193,
0xa679438e,0x49b40821,0xf61e2562,0xc040b340,0x265e5a51,
0xe9b6c7aa,0xd62f105d,0x02441453,0xd8a1e681,0xe7d3fbc8,
0x21e1cde6,0xc33707d6,0xf4d50d87,0x455a14ed,0xa9e3e905,
0xfcefa3f8,0x676f02d9,0x8d2a4c8a,0xfffa3942,0x8771f681,
0x6d9d6122,0xfde5380c,0xa4beea44,0x4bdecfa9,0xf6bb4b60,
0xbebfbc70,0x289b7ec6,0xeaa127fa,0xd4ef3085,0x04881d05,
0xd9d4d039,0xe6db99e5,0x1fa27cf8,0xc4ac5665,0xf4292244,
0x432aff97,0xab9423a7,0xfc93a039,0x655b59c3,0x8f0ccc92,
0xffeff47d,0x85845dd1,0x6fa87e4f,0xfe2ce6e0,0xa3014314,
0x4e0811a1,0xf7537e82,0xbd3af235,0x2ad7d2bb,0xeb86d391};
const unsigned int s[]={7,12,17,22,7,12,17,22,7,12,17,22,7,
12,17,22,5,9,14,20,5,9,14,20,5,9,14,20,5,9,14,20,
4,11,16,23,4,11,16,23,4,11,16,23,4,11,16,23,6,10,
15,21,6,10,15,21,6,10,15,21,6,10,15,21};
const char str16[]="0123456789abcdef";
void mainLoop(unsigned int M[])
{
unsigned int f,g;
unsigned int a=atemp;
unsigned int b=btemp;
unsigned int c=ctemp;
unsigned int d=dtemp;
for (unsigned int i = 0; i < 64; i++)
{
if(i<16){
f=F(b,c,d);
g=i;
}else if (i<32)
{
f=G(b,c,d);
g=(5*i+1)%16;
}else if(i<48){
f=H(b,c,d);
g=(3*i+5)%16;
}else{
f=I(b,c,d);
g=(7*i)%16;
}
unsigned int tmp=d;
d=c;
c=b;
b=b+shift((a+f+k[i]+M[g]),s[i]);
a=tmp;
}
atemp=a+atemp;
btemp=b+btemp;
ctemp=c+ctemp;
dtemp=d+dtemp;
}
unsigned int* add(string str)
{
unsigned int num=((str.length()+8)/64)+1;
unsigned int *strByte=new unsigned int[num*16];
strlength=num*16;
for (unsigned int i = 0; i < num*16; i++)
strByte[i]=0;
for (unsigned int i=0; i <str.length(); i++)
{
strByte[i>>2]|=(str[i])<<((i%4)*8);
}
strByte[str.length()>>2]|=0x80<<(((str.length()%4))*8);
strByte[num*16-2]=str.length()*8;
return strByte;
}
string changeHex(int a)
{
int b;
string str1;
string str="";
for(int i=0;i<4;i++)
{
str1="";
b=((a>>i*8)%(1<<8))&0xff;
for (int j = 0; j < 2; j++)
{
str1.insert(0,1,str16[b%16]);
b=b/16;
}
str+=str1;
}
return str;
}
string getMD5(string source)
{
atemp=A;
btemp=B;
ctemp=C;
dtemp=D;
unsigned int *strByte=add(source);
for(unsigned int i=0;i<strlength/16;i++)
{
unsigned int num[16];
for(unsigned int j=0;j<16;j++)
num[j]=strByte[i*16+j];
mainLoop(num);
}
return changeHex(atemp).append(changeHex(btemp)).append(changeHex(ctemp)).append(changeHex(dtemp));
}
unsigned int main()
{
string ss;
string s=getMD5("abc");
cout<<s;
return 0;
}
|