目录
1. 什么是推荐系统
推荐系统是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。
随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题中的消费者不断流失。
为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。
常见的推荐栏位例如:淘宝的猜你喜欢、看了又看、推荐商品,美团的首页推荐、附近推荐等。
推荐系统是比较偏向于工程类的系统,要做得更加的精确,需要的不仅仅是推荐算法,还有用户意图识别、文本分析、行为分析等,是一个综合性很强的系统。
2. 总体架构
本节介绍的几种推荐系统架构,并不是互相独立的关系,实际的推荐系统可能会用到其中一种或者几种的架构。在实际设计的过程中,读者可以把本文介绍的架构作为一个设计的起点,更多地结合自身业务特点进行独立思
考,从而设计出适合自身业务的系统。
根据响应用户行为的速度不同,推荐系统可以大致分为基于离线训练和在线训练的推荐系统。
2.1 离线推荐
于离线训练的推荐系统架构是最常见的一种推荐系统架构。这里的“离线”训练指的是使用历史一段时间( 比如周或者几周 )的数据进行训练,模型迭代的周期较长(一般 以小时为单位 )。模型拟合的是用户的中长期兴趣。
如下图所示, 一个典型的基于离线训练的推荐系统架构由数据上报、离线训练、在线存储、实时计算和 A/B 测试这几个模块组成。其中,数据上报和离线训练组成了监督学习中的学习系统,而实时计算和 A/B 测试组成了预测系统。另外,除了模型之外,还有一个在线存储模块,用于存储模型和模型需要的特征信息供实时计算模块调用。图中的各个模块组成了训练和预测两条数据流,训练的数据流搜集业务的数据最后生成模型存储于在线存储模块;预测的数据流接受业务的预测请求,通过 A/B 测试模块访问实时计算模块获取预测结果。

数据上报:据上报模块的作用是搜集业务数据组成训练样本。一般分为收集、验证、清洗和转换几个步骤。将收集的数据转化为训练所需要的样本格式,保存到离线存储模块。

离线训练:线训练模块又细分为离线存储和离线计算。实际业务中使用的推荐系统一般都需要处理海量的用户行为数据,所以离线存储模块需要有一个分布式的文件系统或者存储平台来存储这些数据。离线计算常见的操作有:样本抽样、特征工程、模型训练、相似度计算等。
在线存储:因为线上的服务对于时延都有严格的要求。比如,某个用户打开手机 APP ,他肯定希望APP 能够快速响应,如果耗时过长,就会影响用户的体验。一般来说,这就要求推荐系统在几十毫秒以内处理完用户请求返回推荐结果,所以,针对线上的服务,需要有一个专门的在线存储模块,负责存储用于线上的模型和特征数据 。
实时推荐:实时推荐模块的功能是对来自业务的新请求进行预测。1.获取用户特征;2.调用推荐模型;3.结果排序。
在实际应用中,因为业务的物品列表太大,如果实时计算对每 个物品使用复杂的模型进行打分,就有可能耗时过长而影响用户满意度。所以,一种常见的做法是将推荐列表生成分为召回和排序两步。召回的作用是从大量的候选物品中(例如上百万)筛选出一批用户较可能喜欢的候选集 (一般是几百)。排序的作用是对召回得到的相对较小的候选集使用排序模型进行打分。更进一步,在排序得到推荐列表后,为了多样性和运
营的一些考虑,还会加上第三步重排过滤,用于对精排后的推荐列表进行处理。
A/B测试:对于互联网产品来说, A/B 测试基本上是一个必备的模块,对于推荐系统来说也不例外,它可以帮助开发人员评估新算法对客户行为的影响。除了 离线的指标外,一个新的推荐算法上线之前 般都会经过 A/B 测试来测试新算法的有效性。
下图是与之对应的实际系统中各个组件的流转过程。需要注意的是生成推荐列表就已经做完了召回和排序的操作,业务层直接调用API就可以得到这个推荐列表。

2.2 在线训练
对于业务来说,我们希望用户对于上 个广告的反馈 (喜欢或者不 欢,有没有点击 ,可以很快地用于下
一个广告的推荐中。这就要求我们用另 种方法来解决这个问题,这个方法就是在线训练。
基于在线训练的推荐系统架构适合于广告和电商等高维度大数据量且对实时性要求很高的场景 相比较基于离线训练的推荐系统,基于在线训练的推荐系统不区分训练和测试阶段,每个回合都在学习,通过实时的反馈来调整策略。 方面,在线训练要求其样本、特征和模型的处理都是实时的,以便推荐的内容更快地反映用户实时的喜好;另一方面,因为在线训练井不需要将所有的训练数据都存储下来,所以不需要巨大的离线存储开销,使得系统具有很好的伸缩性,可以支持超大的数据量和模型。

- 样本处理:和基于离线训练的推荐系统相比,在线训练在数据上报阶段的主要不同体现在样本处理上。,对于离线训练来说,上报后的数据先是被存储到一个分布式文件系统,然后等待离线计算任务来对样本进行处理;对于在线训练来说,对样本的去重、过滤和采样等计算都需要实时进行。
- 实时特性:实时特征模块通过实时处理样本数据拼接训练需要的特征构造训练样本,输入流式训练模块用于更新模型。该模块的主要的功能是特征拼接和特征工程。
- 流式训练:、流式训练模块的主要作用是使用实时训练样本来更新模型。推荐算法中增量更新部分的计算,通过流式计算的方式来进行更新。在线训练的优势之一,是可以支持模型的稀疏存储。训练方面,在线模型不一定都是从零开始训练,而是可以将离线训练得到的模型参数作为基础,在这个基础上进行增量训练。
- 模型存储和加载:模型一般存储在参数服务器中。模型更新后,将模型文件推送到线上存储,并由线上服务模块动态加载。
3. 特征数据
要训练推荐模型,就需要先收集用户的行为数据生成特征向量以后才能进行训练,而一个特征向量由特征以及特征的权重组成,在利用用户行为计算特征向量时需要考虑以下因素。
- 用户行为的种类:在一个网站中,用户可以对物品产生很多不同种类的行为。用户可以浏览物品、单击物品的链接、收藏物品、给物品打分、购买物品、评论物品、给物品打上不同的标签、和好友分享物品、搜索不同的关键词等。这些行为都会对物品特征的权重产生影响,但不同行为的影响不同,大多时候很难确定什么行为更加重要,一般的标准就是用户付出代价越大的行为权重越高。
- 用户行为产生的时间:一般来说,用户近期的行为比较重要,而用户很久之前的行为相对比较次要。因此,如果用户最近购买过某一个物品,那么这个物品对应的特征将会具有比较高的权重。
- 用户行为的次数:有时用户对一个物品会产生很多次行为。比如用户会听一首歌很多次,看一部电视剧的很多集等。因此用户对同一个物品的同一种行为发生的次数也反映了用户对物品的兴趣,行为次数多的物品对应的特征权重越高。
- 物品的热门程度:如果用户对一个很热门的物品产生了行为,往往不能代表用户的个性,因为用户可能是在跟风,可能对该物品并没有太大兴趣,特别是在用户对一个热门物品产生了偶尔几次不重要的行为(比如浏览行为)时,就更说明用户对这个物品可能没有什么兴趣,可能只是因为这个物品的链接到处都是,很容易点到而已。反之,如果用户对一个不热门的物品产生了行为,就说明了用户的个性需求。因此,推荐引擎在生成用户特征时会加重不热门物品对应的特征的权重。
- 数据去燥:对样本做去噪。对于数据中混杂的刷单等类作弊行为的数据,要将其排除出训练数据,否则它会直接影响模型的效果;样本中的缺失值也要做处理。
- 正负样本均衡:一般我们收集用户的行为数据都是属于正样本,造成了严重的不平衡。所以对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,保证每个用户的正负样本数目相当。
- 特征组合:我们需要考虑特征与特征之间的关系。例如在美团酒店搜索排序中,酒店的销量、价格、用户的消费水平等是强相关的因素,用户的年龄、位置可能是弱相关的因素,用户的ID是完全无关的因素。在确定了哪些因素可能与预测目标相关后,我们需要将此信息表示为数值类型,即为特征抽取的过程。除此之外,用户在App上的浏览、交易等行为记录中包含了大量的信息,特征抽取则主要是从这些信息抽取出相关因素,用数值变量进行表示。常用的统计特征有计数特征,如浏览次数、下单次数等;比率特征,如点击率、转化率等;统计量特征,如价格均值、标准差、分位数、偏度、峰度等。
4. 协同过滤算法
协同过滤算法起源于 1992 年,被 Xerox 公司用于个性化定制邮件系统。Xerox 司的用户需要在数十种主题中选择三到五种主题,协同过滤算法根据不同的主题过滤邮件,最终达到个性化的目的。
协同过滤算法分为基于物品的协同过滤和基于用户的协同过滤,输出结果为 TOPn 的推荐列表。
4.1 基于物品的协同过滤(ItemCF)
基于物品的协同过滤算法的核心思想:给用户推荐那些和他们之前喜欢的物品相似的物品。
基于物品的协同过滤算法首先计算物品之间的相似度, 计算相似度的方法有以下几种:
基于共同喜欢物品的用户列表计算

在此,分母中 N(i) 是购买物品 i 的用户数,N(j) 是购买物品 j 的用户数,而分子
 是同时购买物品i 和物品 j 的用户数。。可见上述的公式的核心是计算同时购买这件商品的人数比例 。当同时购买这两个物品人数越多,他们的相似度也就越高。另外值得注意的是,在分母中我们用了物品总购买人数做惩罚,也就是说某个物品可能很热门,导致它经常会被和其他物品一起购买,所以除以它的总购买人数,来降低它和其他物品的相似分数。
是同时购买物品i 和物品 j 的用户数。。可见上述的公式的核心是计算同时购买这件商品的人数比例 。当同时购买这两个物品人数越多,他们的相似度也就越高。另外值得注意的是,在分母中我们用了物品总购买人数做惩罚,也就是说某个物品可能很热门,导致它经常会被和其他物品一起购买,所以除以它的总购买人数,来降低它和其他物品的相似分数。基于余弦的相似度计算
上面的方法计算物品相似度是直接使同时购买这两个物品的人数。但是也有可能存在用户购买了但不喜欢的情况 所以如果数据集包含了具体的评分数据 我们可以进一步把用户评分引入到相似度计算中 。
其中
是用户 k 对物品 i 的评分,如果没有评分则为 0。
热门物品的惩罚
对于热门物品的问题,可以用如下公式解决:

当
时,N(i) 越小,惩罚得越厉害,从而会使热 物品相关性分数下降。
4.2 基于用户的协同过滤(UserCF)
基于用户的协同过滤(User CF )的原理其实是和基于物品的协同过滤类似的。所不同的是,基于物品的协同过滤的原理是用户 U 购买了 A 物品,推荐给用户 U 和 A 相似的物品 B、C、D。而基于用户的协同过滤,是先计算用户 U 与其他的用户的相似度,然后取和 U 最相似的几个用户,把他们购买过的物品推荐给用户U。
为了计算用户相似度,我们首先要把用户购买过物品的索引数据转化成物品被用户购买过的索引数据,即物品的倒排索引:

建立好物品的倒排索引后,就可以根据相似度公式计算用户之间的相似度:

其中 N(a) 表示用户 a 购买物品的数量,N(b) 表示用户 b 购买物品的数量,N(a)∩N(b) 表示用户 a 和 b 购买相同物品的数量。有了用户的相似数据,针对用户 U 挑选 K 个最相似的用户,把他们购买过的物品中,U 未购买过的物品推荐给用户 U 即可。
4.3 矩阵分解
上述计算会得到一个相似度矩阵,而这个矩阵的大小和纬度都是很大的,需要进行降维处理,用到的是SVD的降维方法,具体可以参考我之前写的降维方法:2.5 降维方法
基于稀疏自编码的矩阵分解
矩阵分解技术在推荐领域的应用比较成熟,但是通过上一节的介绍,我们不难发现矩阵分解本质上只通过一次分解来对 原矩阵进行逼近,特征挖掘的层次不够深入。另外矩阵分解也没有运用到物品本身的内容特征,例如书本的类别分类、音乐的流派分类等。随着神经网络技术的兴起,笔者发现通过多层感知机,可以得到更加深度的特征表示,并且可以对内容分类特征加以应用。首先,我们介绍一下稀疏自编码神经网络的设计思路。
基础的自编码结构
最简单的自编码结构如下图,构造个三层的神经网络,我们让输出层等于输入层,且中间层的维度远低于输入层和输出层,这样就得到了第一层的特征压缩。

简单来说自编码神经网络尝试学习中间层约等于输入层的函数。换句话说,它尝试逼近一个恒等函数。如果网络的输入数据是完全随机的,比如每一个输入都是一个跟其他特征完全无关的独立同分布高斯随机变 ,那么这一压缩表示将会非常难于学习。但是如果输入数据中隐含着 些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。
多层结构
基于以上的单层隐藏层的网络结构,我们可以扩展至多层网络结构,学习到更高层次的抽象特征。

5. 隐语义模型
5.1 基本思想
推荐系统中一个重要的分支,隐语义建模。隐语义模型LFM:Latent Factor Model,其核心思想就是通过隐含特征联系用户兴趣和物品。
过程分为三个部分,将物品映射到隐含分类,确定用户对隐含分类的兴趣,然后选择用户感兴趣的分类中的物品推荐给用户。它是基于用户行为统计的自动聚类。
隐语义模型在Top-N推荐中的应用十分广泛。常用的隐语义模型,LSA(Latent Semantic Analysis),LDA(Latent Dirichlet Allocation),主题模型(Topic Model),矩阵分解(Matrix Factorization)等等。
首先通过一个例子来理解一下这个模型,比如说有两个用户A和B,目前有用户的阅读列表,用户A的兴趣涉及侦探小说,科普图书以及一些计算机技术书,而用户B的兴趣比较集中在数学和机器学习方面。那么如何给A和B推荐图书呢?
对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后在给他们推荐那些用户喜欢的其他书。
对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如用户B 看了很多数据挖掘方面的书,那么可以给他推荐机器学习或者模式识别方面的书。
还有一种方法就是使用隐语义模型,可以对书和物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
5.2 模型理解
- 如何给物品进行分类?
- 如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?
- 对于一个给定的类,选择哪些属于这个类的物品推荐给用户,以及如何确定这些物品在一个类中的权重?
为了解决上面的问题,研究人员提出:为什么我们不从数据出发,自动地找到那些类,然后进行个性化推荐,隐语义分析技术因为采取基于用户行为统计的自动聚类,较好地解决了上面的问题。隐语义分析技术从诞生到今天产生了很多著名的模型和方法,其中和推荐技术相关的有pLSA,LDA,隐含类别模型(latent class model), 隐含主题模型(latent topic model), 矩阵分解(matrix factorization)。
LFM通过如下公式计算用户 u 对物品 i 的兴趣:
这个公式中 和
是模型的参数,其中
度量了用户 u 的兴趣和第 k 个隐类的关系,而
度量了第 k 个隐类和物品 i 之间的关系。那么,下面的问题就是如何计算这两个参数。
对最优化理论或者机器学习有所了解的读者,可能对如何计算这两个参数都比较清楚。这两个参数是从数据集中计算出来的。要计算这两个参数,需要一个训练集,对于每个用户u,训练集里都包含了用户u喜欢的物品和不感兴趣的物品,通过学习这个数据集,就可以获得上面的模型参数。
6. 排序算法
在工业应用中,推荐系统通常可分为两部分,召回和排序。协同过滤属于召回的算法,从召回中得到一个比较小的推荐列表,然后经过排序之后才会输出到最终的推荐列表里,是一个有序的推荐列表。
这个过程会从几千万 item 中筛选出几百或者上千的候选集,然后在排序阶段选出30个给到每位用户。这个排序可理解为一个函数,F(user, item, context),输入为用户、物品、环境,输出一个0到1之间的分数,取分数最高的几首。这一过程通常称为 CTR 预估。那么 F 函数常见的运作形式有:
Logistic Regression
最简单的是逻辑回归(Logistic Regression),一个广义线性模型。拿某 user 的用户画像(一个向量)比如
[3, 1],拼接上某 item 的物品画像比如[4, 0],再加上代表 context 的向量[0, 1, 1]后得到[3, 1, 4, 0, 0, 1, 1],若该 user 曾与该 item 发生过联系则 label 为1,这些加起来是一个正样本,同时可以将用户“跳过”的 item 或热门的却没有与用户产生过联系的 item 作为负样本,label 为0。按照这样的输入和输出就可以训练出排序算法了。详细模型见:2. 逻辑回归GBDT
使用梯度提升决策树(GBDT) 的方案也可以解决这个排序的问题,只是模型与 LR 不一样。GBDT作为集成模型,会使用多棵决策树,每棵树去拟合前一棵树的残差来得到很好的拟合效果。一个样本输入到一棵树中,会根据各节点的条件往下走到某个叶子节点,将此节点值置为1,其余置为0。详细模型算法见:3.2 GBDT
GBDT+LR
GBDT与LR的stacking模型相对于只用GBDT会有略微的提升,更大的好处是防止GBDT过拟合。升级为GBDT+LR后,线上效果提升了约5%,并且因为省去了对新特征进行人工转换的步骤,增加特征的迭代测试也更容易了。
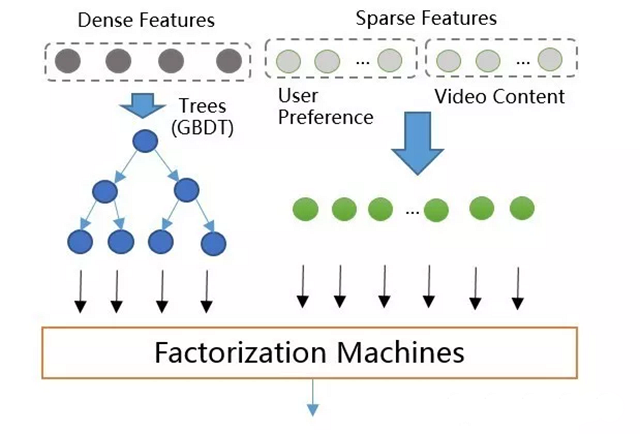
GBDT+FM
GBDT是不支持高维稀疏特征的,如果将高维特征加到LR中,一方面需要人工组合高维特征,另一方面模型维度和计算复杂度会是O(N^2)级别的增长。所以设计了GBDT+FM的模型如图所示,采用Factorization Machines模型替换LR。
Factorization Machines(FM)模型如下所示:
具有以下几个优点
①前两项为一个线性模型,相当于LR模型的作用
②第三项为一个二次交叉项,能够自动对特征进行交叉组合
③通过增加隐向量,模型训练和预测的计算复杂度降为了O(N)
④支持稀疏特征。几个优点,使的GBDT+FM具有了良好的稀疏特征支持,FM使用GBDT的叶子结点和稀疏特征(内容特征)作为输入,模型结构示意图如下,GBDT+FM模型上线后相比GBDT+LR在各项指标的效果提升在4%~6%之间。
DNN+GBDT+FM
GBDT+FM模型,对embedding等具有结构信息的深度特征利用不充分,而深度学习(Deep Neural Network)能够对嵌入式(embedding)特征和普通稠密特征进行学习,抽取出深层信息,提高模型的准确性,并已经成功应用到众多机器学习领域。因此我们将DNN引入到排序模型中,提高排序整体质量。
DNN+GBDT+FM的ensemble模型架构如图所示,FM层作为模型的最后一层,即融合层,其输入由三部分组成:DNN的最后一层隐藏层、GBDT的输出叶子节点、高维稀疏特征。DNN+GBDT+FM的ensemble模型架构介绍如下所示,该模型上线后相对于GBDT+FM有4%的效果提升。
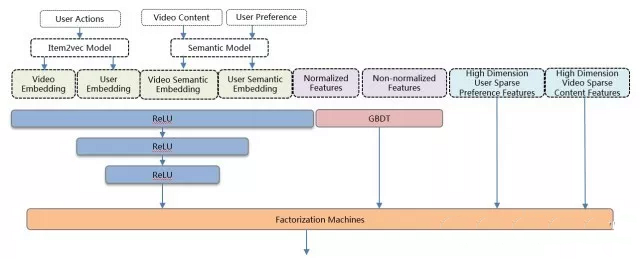
使用分布式的TensorFlow进行训练,使用基于TensorFlow Serving的微服务进行在线预测,DNN+GBDT+FM的ensemble模型使用的是Adam优化器。Adam结合了The Adaptive Gradient Algorithm(AdaGrad)和Root Mean Square Propagation(RMSProp)算法。具有更优的收敛速率,每个变量有独自的下降步长,整体下降步长会根据当前梯度进行调节,能够适应带噪音的数据。实验测试了多种优化器,Adam的效果是最优的。
工业界DNN ranking现状
- Youtube于2016年推出DNN排序算法。
- 上海交通大学和UCL于2016年推出Product-based Neural Network(PNN)网络进行用户点击预测。PNN相当于在DNN层做了特征交叉,我们的做法是把特征交叉交给FM去做,DNN专注于深层信息的提取。
- Google于2016年推出Wide And Deep Model,这个也是我们当前模型的基础,在此基础上使用FM替换了Cross Feature LR,简化了计算复杂度,提高交叉的泛化能力。
- 阿里今年使用attention机制推出了Deep Interest Network(DIN)进行商品点击率预估,优化embedding向量的准确性,值得借鉴。
7. 评估测试
7.1 A/B测试
新的推荐模型上线后要进行A/B测试,将它和旧的算法进行比较。
AB测试是一种很常用的在线评测算法的实验方法。它通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种不同的评测指标比较不同算法,比如可以统计不同组用户的点击率,通过点击率比较不同算法的性能。对AB测试感兴趣的读者可以浏览一下网站http://www.abtests.com/ ,该网站给出了很多通过实际AB测试提高网站用户满意度的例子,从中我们可以学习到如何进行合理的AB测试。
切分流量是AB测试中的关键,不同的层以及控制这些层的团队需要从一个统一的地方获得自己AB测试的流量,而不同层之间的流量应该是正交的。
“正交性”是从几何中借来的术语。如果两条直线相交成直角,他们就是正交的。用向量术语来说,这两条直线互不依赖。
下图是一个简单的AB测试系统。用户进入网站后,流量分配系统决定用户是否需要被进行AB测试,如果需要的话,流量分配系统会给用户打上在测试中属于什么分组的标签。然后用户浏览网页,而用户在浏览网页时的行为都会被通过日志系统发回后台的日志数据库。此时,如果用户有测试分组的标签,那么该标签也会被发回后台数据库。在后台,实验人员的工作首先是配置流量分配系统,决定满足什么条件的用户参加什么样的测试。其次,实验人员需要统计日志数据库中的数据,通过评测系统生成不同分组用户的实验报告,并比较和评测实验结果。

当完成了AB测试后,根据指标结果,如果优于之前的推荐算法,那么旧的算法就可以替换成新的了。
7.2 其它评估方法
模型准备就绪后,一般会先通过离线指标来评估模型的好坏, 然后再决定能否上线测试。离线算法评估常见的指标包括准确率、覆盖度 、多样性、新颖性和 UC 等。在线测试一般通过 A/B 测试进行,常见的指标有点击率、用户停留时间、 广告收入等,需要注意分析统计显著性。同时,需要注意短期的指标和长期的指标相结合, 一些短期指标的提升有时候反而会导致长期指标下降 比如 ,经常推荐美女或者搞笑类的内容会带来短期的点击率提高,但是可能会引起长期的用户粘性下降。设计者需要从自己的产品角度出发,根据产品的需要制定评估指标,这样才能更好地指导推荐系统的优化方向。常见的评价指标如下:

8. 推荐系统冷启动问题
冷启动( cold start )在推荐系统中表示该系统积累数据量过少,无法给新用户作个性化推荐的问题,这是产品推荐的一大难题。每个有推荐功能的产品都会遇到冷启动的问题。一方面,当新商品时上架 会遇到冷启动的问题,没有收集到任何一个用户对其浏览、点击或者购买的行为,也无从判断如何将商品进行推荐;另一方面,新用户到来的时候,如果没有他在应用上的行为数据,也无法预测其兴趣,如果给用户的推荐千篇律,没有亮点,会使用户在一开始就对产品失去兴趣,从而放弃使用。所以在冷启动的时候要同时考虑用户的冷启动和物品的冷启动。
基本上,冷启动题可以分为以下三类。
8.1 用户冷启动
用户冷启动主要解决如何给新用户作个性化推荐的问题。当新用户到来时,我 没有他的行为数据,所以也无法根据他的历史行为预 其兴趣,从而无法借此给他做个性化推荐。解决方法参考以下:
- 利用用户的账号信息。
- 利用用户的手机 IMEI 号进行冷启动。
- 制造选工页,让用户选择自己感兴趣的点后,即时生成粗粒度的推荐。
8.2 物品冷启动
物品冷启动主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题。解决方法参考以下:
- 利用物品的内容、分类信息。
- 利用专家标注的数据。
8.3 系统冷启动
系统冷启动主要解决如何在一个新开发的网站上(还没有用户,也没有用户行为,只有一些物品的信息)设计个性推荐系统,从而在产品刚上线时就让用户体验到个性 推荐服务这一问题。
9. 参考文献
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
欢迎大家加入讨论!共同完善此项目!群号:【541954936】